

Simple: Tener varias redes neuronales similares a GPT-3 en tamaño, pero especializadas en distintas áreas, que conviven en una sola, gran red.
Esto fue lo que el divulgador DotCSV compartió en su último video, según una filtración de un hacker reconocido. [1]
Lo que debes saber: Esta arquitectura se la conoce como MoE o mixture of experts, es equivalente a tener muchos expertos que son consultados según el área de expertise, por ejemplo uno en código de programación, otro de escritura y así!

La primera vez que escuche de esto pensé, que habíamos vuelto unos años atrás donde teníamos modelos en lo que se conoce en el machine learning tradicional como bagging. Básicamente juntar varios modelos en uno solo cuyo resultado final es superior al haber utilizado uno solo de ellos.
"Ruteando" la respuesta
Este no es el caso que comenté anteriormente, ya que que MoE tiene un único punto de entrada llamado Router, el cual se encarga de encaminar la respuesta haciendo el mejor modelo, o experto.
El modelo MoE de Mistral permite que para cada pregunta, solo 2 de los 8 expertos se activen, y esto lo realiza en una magnifica tarea de elegir al experto token a token.
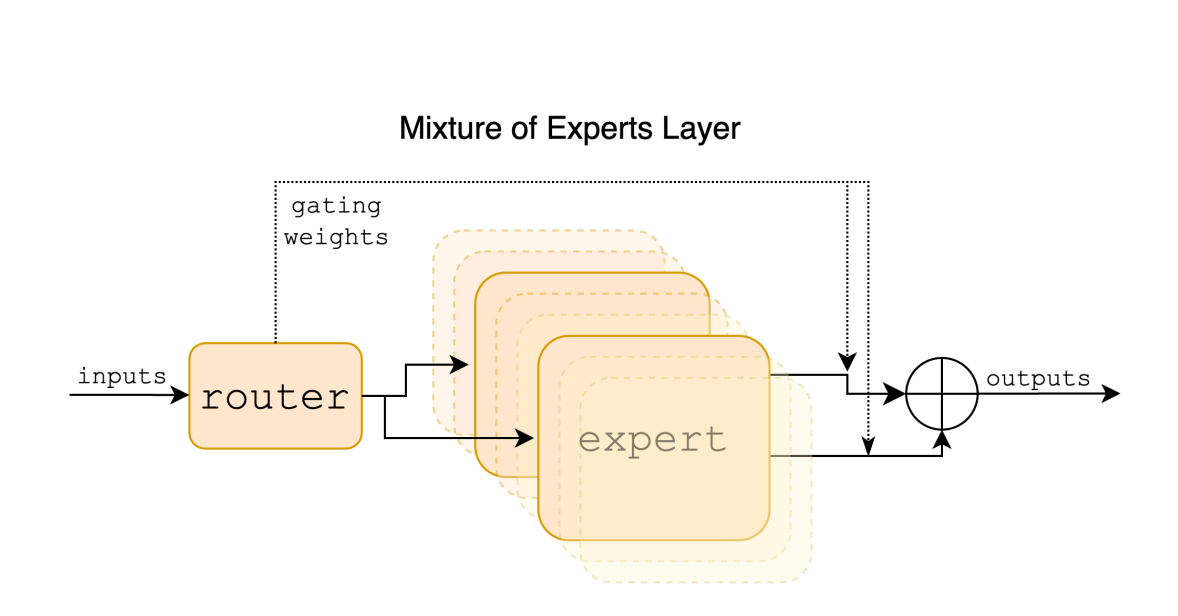
El resultado final es un promedio de lo que dijeron los 2 expertos activados.
Lo interesante es que esta arquitectura permite devolver resultados superiores a otro modelo popular como el popular LLama 2 ¡pero 6 veces más rápidas!
En números, Mixtral 8x7B utiliza 12.9 de los 46.7 mil millones de parámetros. Eso es un 27% 💸
¿Y cómo rankea?
Y más interesante aún, es que según un ranking reconocido que se valida con preferencia humana, es decir que ante una consulta nueva (prompt), se nos presentan 2 respuestas de modelos al azar. El humano califica la mejor respuesta y es así como se obtiene una preferencia. Ingenioso.
Mixtral es el único opensource dentro del top 10! (a la fecha de publicación de este post).
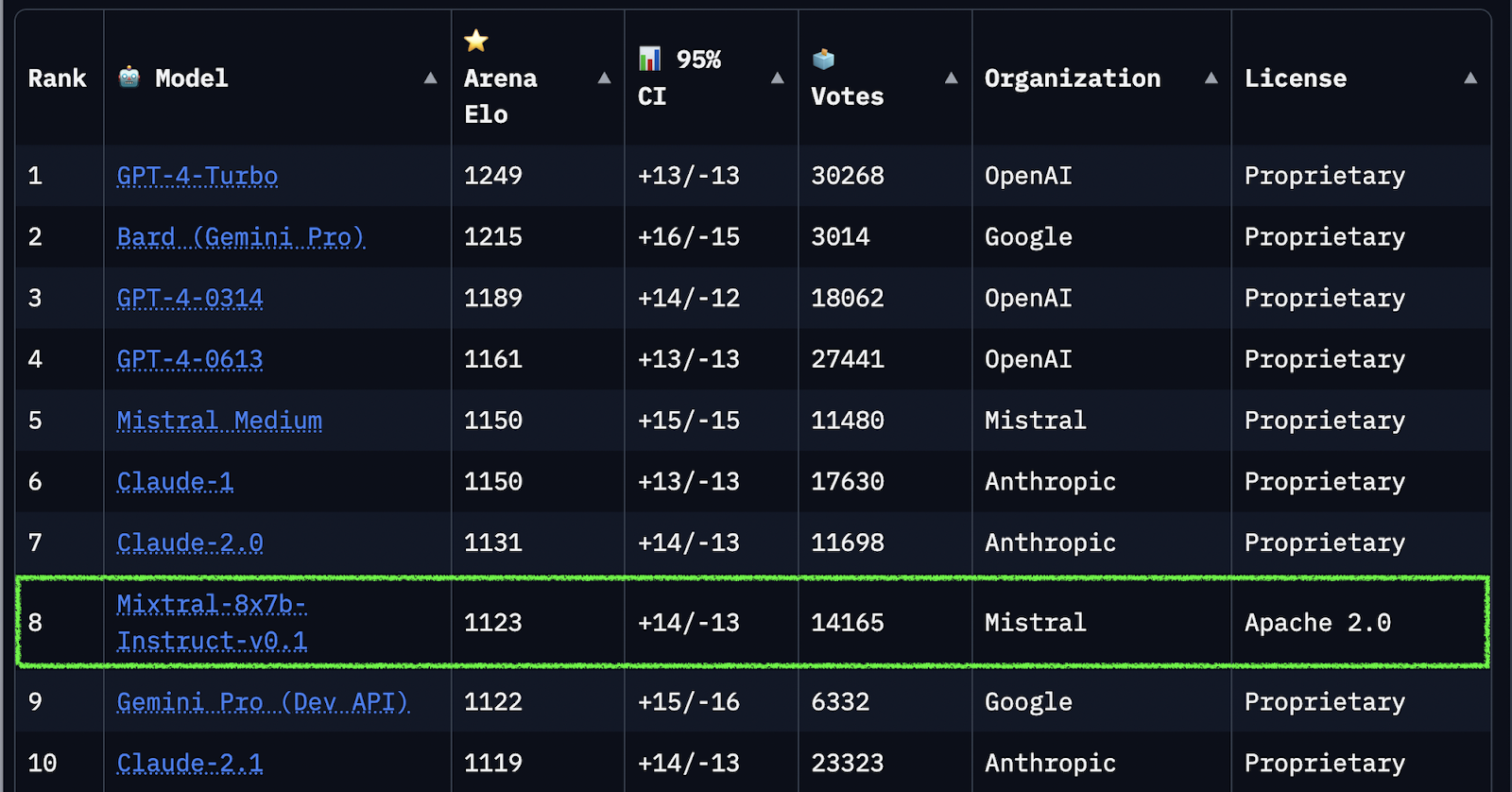
Mención especial para Bard que ya está pisando el 2do lugar.
En el paper del Mixtral, además se observa la comparación frente a 2 referentes de los modelos de lenguaje, LLaMA 2 70B y el famoso GPT-3.5
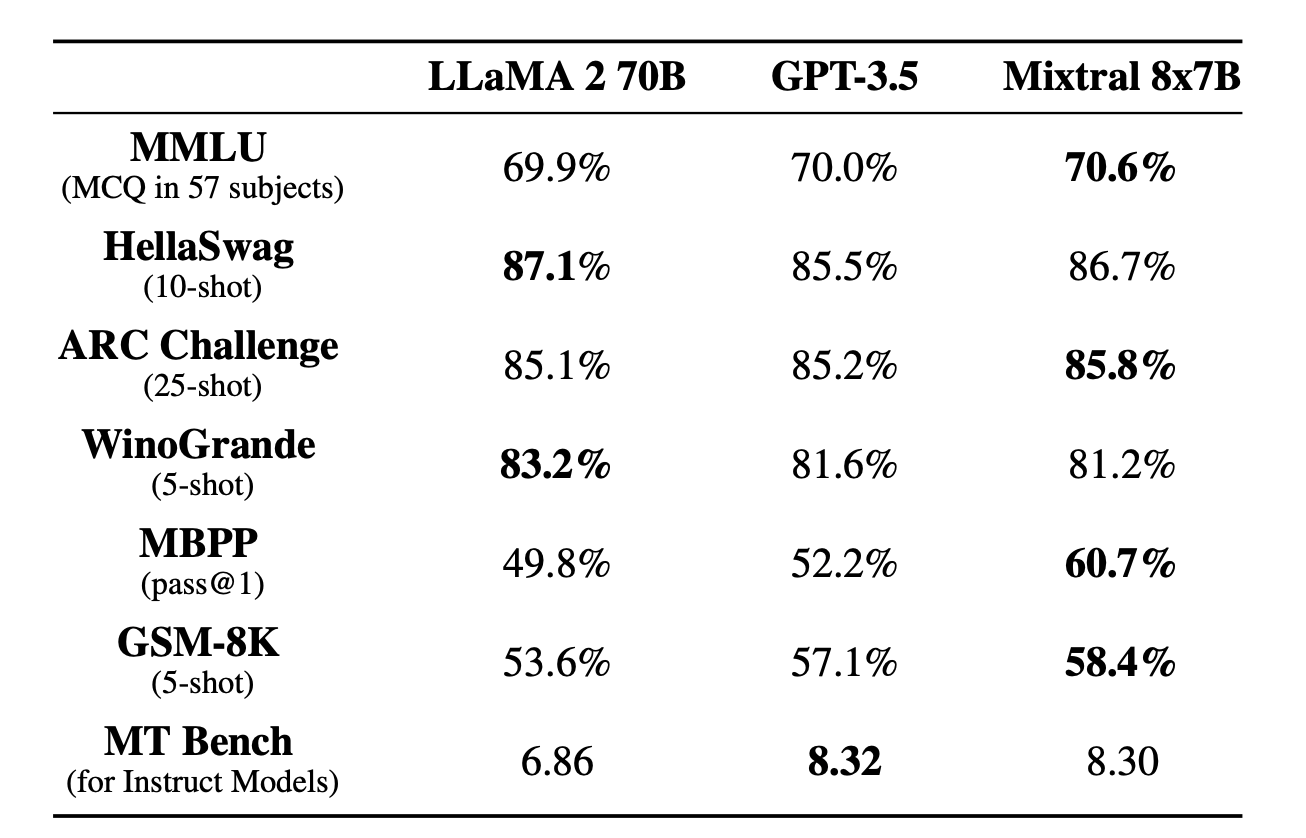
Y sacó el valor más alto en MMLU, el cual es una métrica que evalua a un modelo en distintas tareas. Es el que se toma de referencia, aunque como siempre menciono, no debe ser la única manera de validar estos modelos.
La puesta en productivo, la velocidad de respuesta, y la calidad frente a tareas no vistas es clave.
Conclusión
Mistral AI es una de las empresas que te recomendamos seguir en IA este 2024, la cual junto a Meta y su modelo LLama empujen la tendencia de generar modelos mucho más chicos, pero especializados en una tarea puntual.
Eficiencia y costo en el radar de los modelos largos de lenguaje.
🧑🏽💻 Y si quieres aprender estas temas aplicadas al mundo laboral, probablemente nuestros bootcamps sean tu opción:
Referencias
- [1] Video DotCSV
- [2] Paper Mixtral