

¡Qué nombre! Modelos de lenguaje neuronales, también conocidos como "neural language model". Y si están pensando en GPT-3; sí, éste pertenece a los language model.
Su objetivo es predecir próxima palabra dada una oración, modelo típico de Seq2Seq pero de a una palabra a la vez.
Ejemplo:
in = ['the', 'cat', 'is', 'under', 'the']
out = ['table']
Este post tiene algunas consideraciones para la validación de estos modelos.
Empecemos 🚀
Partimos de una arquitectura típica para estos proyectos (en Keras): embedding + LSTM y un dense con softmax.
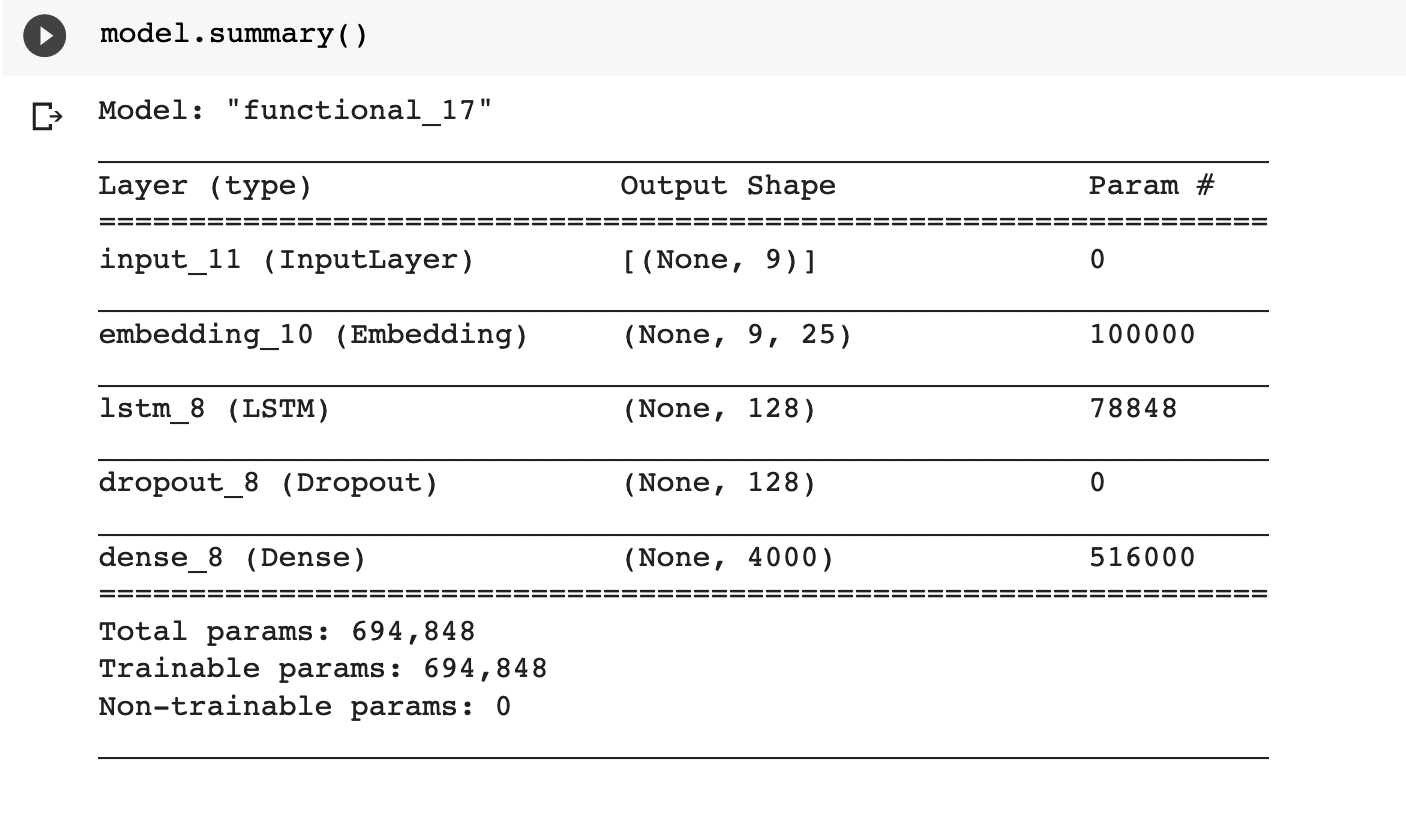
Se entrena el modelo 10 épocas (pocas), la distribución del token de salida se ve así:
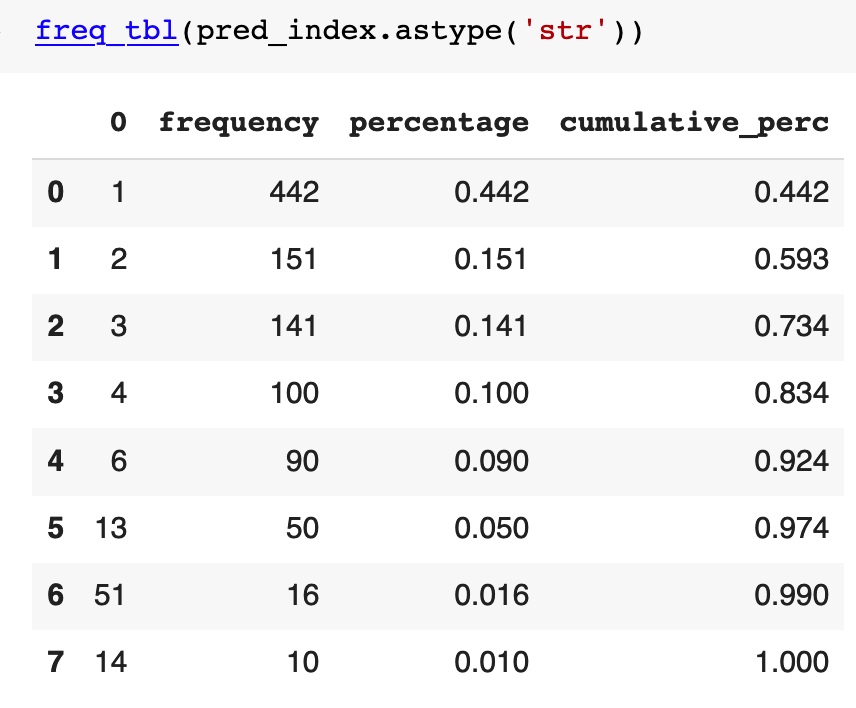
La columna '0' representa el token id predicho (son palabras), de un total de 4000 tokens, el modelo sólo predice 8. De hecho esta correlacionado con el token id, donde un valor chico implica que alta representatividad.
Algunos tips para mejorar esto son:
- Reducir la cantidad de tokens a aquellos que aparezcan al menos X veces (en este caso se selecciono el top 4000 sobre un total de 5000).
- Quitar las stop words (en este ejemplo se las dejé)
Esto es un claro efecto de que la red aprende mejor las palabras (tokens) que mas veces aparecen.
El accuracy no debería ser tan importante, siempre y cuando el loss vaya disminuyendo:
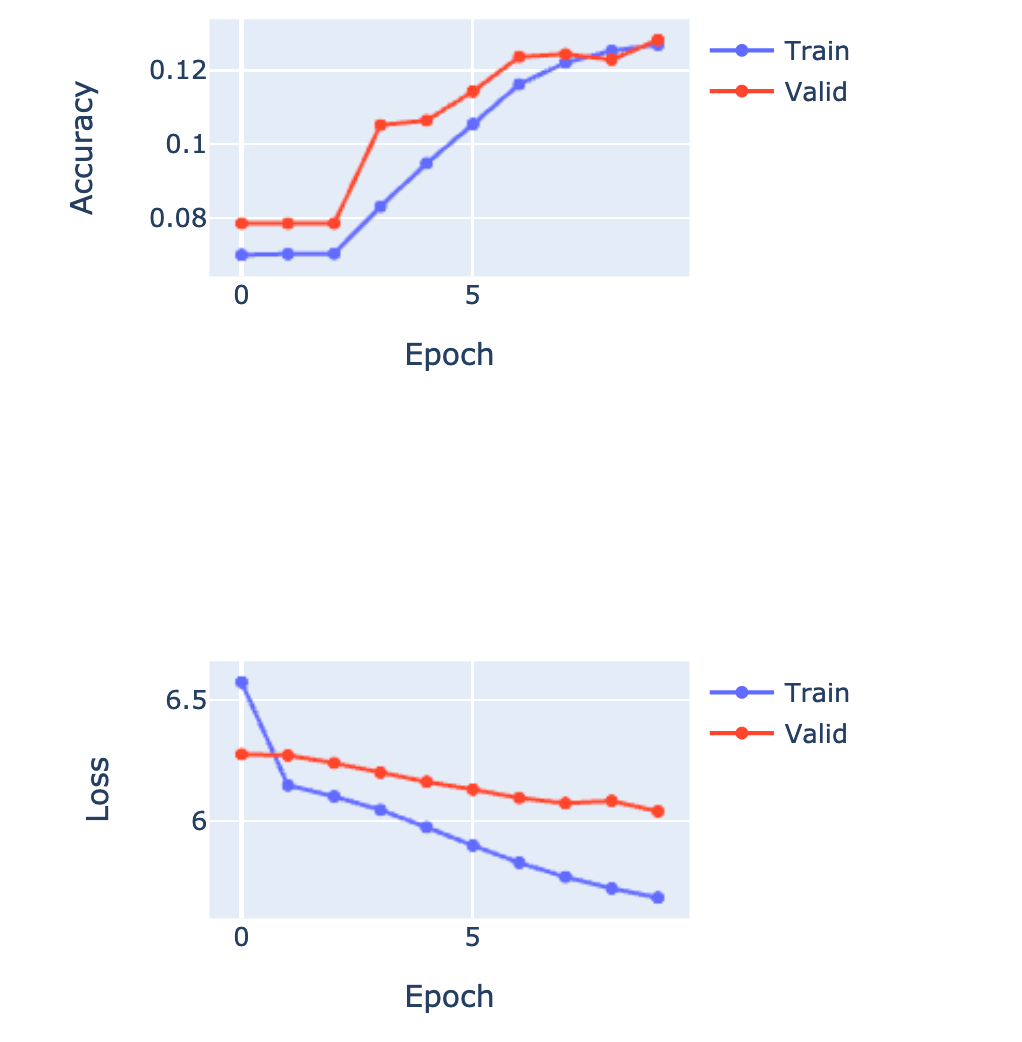
Entrenando unas 15 épocas más, podemos ver cómo el modelo empieza a predecir más tokens:
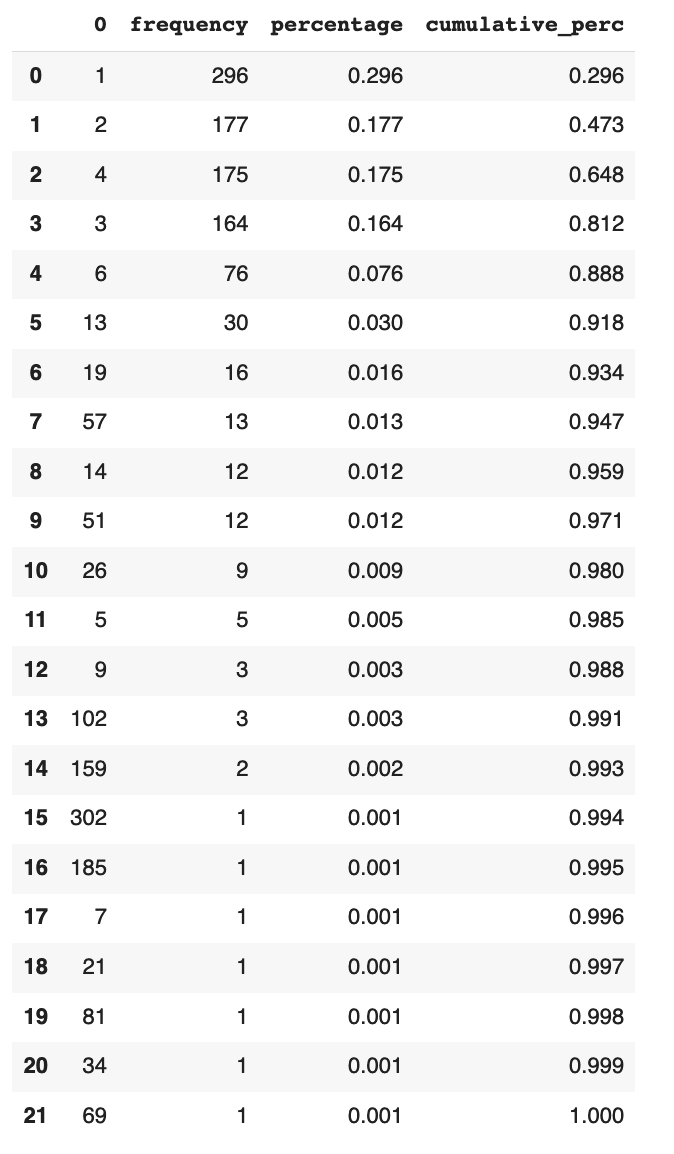
Podemos ver que palabras representa cada token:

Y no, este resultado no es extraño: https://en.wikipedia.org/wiki/Most_common_words_in_English
Chequeo de la densidad de predicciones
Otros de los sanity check para hacer, es el de ver cuales son las top 5 predicciones, por cada input.
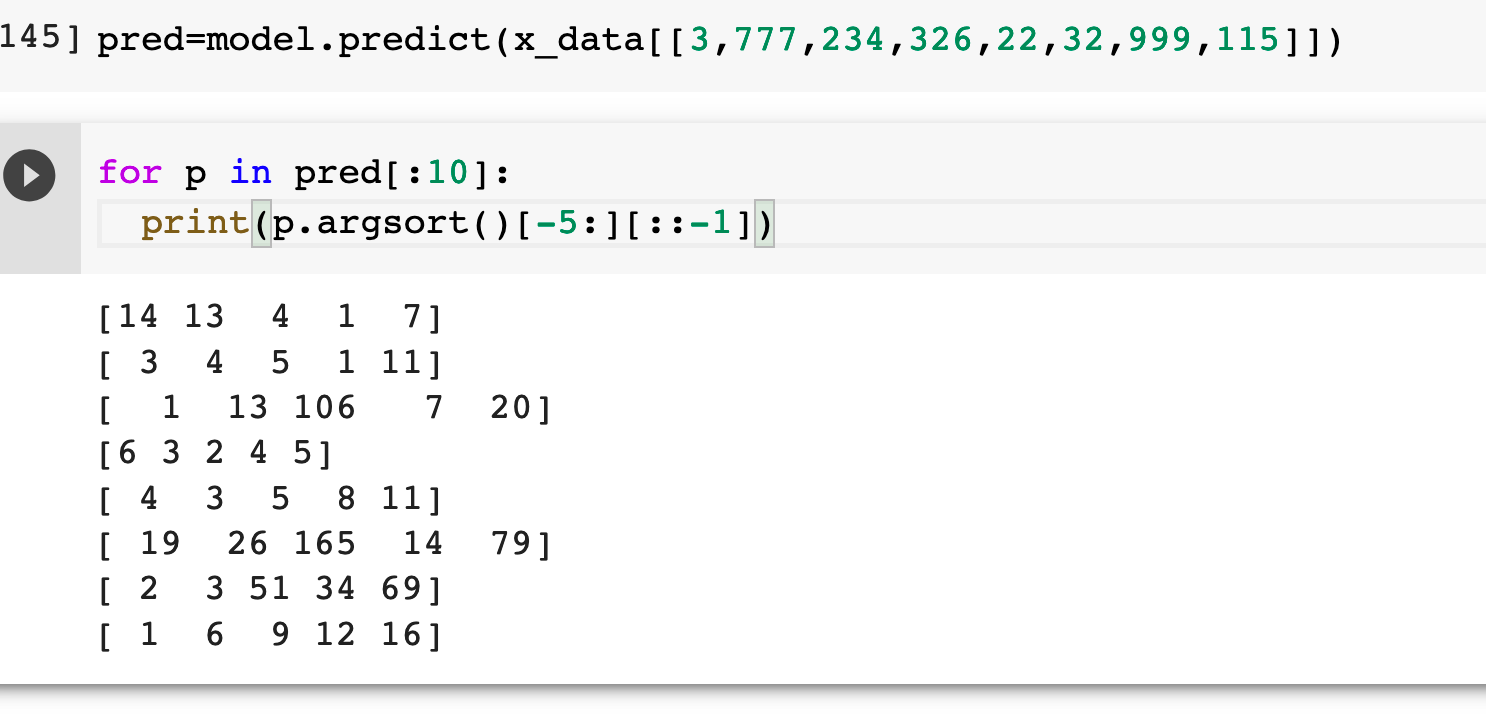
Como el softmax retorna un vector de probabilidades, podemos chequear para distintos casos de entrada (3, 777, etc); cual es el top 5 de las predicciones.
Fila 1: la predicción es 14, pero la 2da probabilidad mas alta es el 13, y la 3ra el 4.
¿Qué se encuentra analizando la fila 2 y la fila 5?
Este sería un ejemplo en dónde el modelo predice lo mismo (no importa la palabra, siempre devuelve como primeras 3 opciones los tokens 1, 2 y 3):

Analizando Caso 1
Se ve (a ojo) que esta bien distribuido. ¿Por qué es útil? Porque si usamos el concepto de temperatura para seleccionar muestreando la distribución, podemos esperar predicciones diversas.
For high temperatures (𝜏→∞), all [samples] have nearly the same probability and the lower the temperature, the more expected rewards affect the probability. For a low temperature (𝜏→0+), the probability of the [sample] with the highest expected reward tends to 1.

Nota: No se está hablando de la calidad de las predicciones, sino mas bien de otorgar resultados diversos.
Pensamientos finales
Hay muchas maneras de validar los modelos de lenguaje, mas allá de las métricas como accuracy.
Analizar las predicciones y distribución de tokens nos da una idea de si el resultado es el esperado.
Me parece sumamente interesante el hecho de ofrecer resultados no determínisticos en las predicciones donde la salida es tan diversa (palabras!).
Justamente en modelos de lenguaje, el usar el parámetro de temperatura puede ayudarnos a saltar de lo establecido, pero claro podemos incurrir en que el texto no tenga sentido.
Si quieren empezar o profundizar en Deep Learning, aprender los fundamentos orientado a la práctica, tenemos en Escuela de Datos Vivos el curso Deep Learning 360 ⚡️