

Desde que comencé en IA, pasé de ver grandes avances cada un par de años, a ver disrupciones que rompen el estado del arte semana a semana.
Se publicó Sora de OpenAI, creando videos que no pueden distinguirse de la realidad. Otro hito en IA.
Tengamos este contexto: Hace tan solo 2 años, no existía la generación de videos.
Al leer todo el post te llevarás un contexto general de IA hoy basado en Sora, y hablaremos de lo que para mí es un ingrediente secreto: los patches. Debajo le dedico una sección entera.
Empecemos! 🚀
¿Qué es Sora de OpenAI?
Es el modelo text-to-video de generación de video más avanzado hasta el momento. Sora es el estado del arte:
Esto que vieron recién y parece un trailer de un estudio de Hollywood, es un video generado en base a un texto ó prompt, sin edición.
Sora permite:
- Crear clips de hasta 60 segundos, con posibilidad de extenderlo
- Variar la resolución, formatos, posición de la cámara
- Combinar 2 videos en 1, y más...
Hay otras empresas como PikaLabs, RunwayML, pero ninguno de esta calidad.
¿Cómo funciona Sora?
Es un modelo de difusión basada en la arquitectura estrella de IA por excelencia: transformers.
Hay muy poca información técnica hasta el momento, sin embargo voy a destacar lo más importante de lo que se conoce ahora.
Ufff cuántos términos! Empecemos: ¿Qué es un modelo de difusión?
Las IAs, son redes neuronales que se entrenan. El cómo se le presentan los datos es clave para determinar que puede hacer.
Resumidamente en difusión durante el entrenamiento se busca es ir agregando ruido a cada imágen (si, puntitos de colores aleatorios).

Pareciera que no tiene mucho sentido, pero al cabo de su entrenamiento este modelo aprende a sacar el ruido de la imágen para que se descubra la imágen.
Parecido a un escultor, ¿no?
Si tomamos la referencia publicada por los creadores, vemos que a partir de un conjunto de imágenes (patches) la IA aprende a eliminar el ruido.
A mayor iteración, mayor calidad del video
De esta forma para cada patch se va descubriendo de forma iterativa y condicionada por el prompt, el video que el usuario espera. Por lo tanto: más iteraciones para generar el video, más calidad de la generación de imágenes, más costo computacional.

Sigue como desafío el balance entre iteraciones y videos que sean de calidad
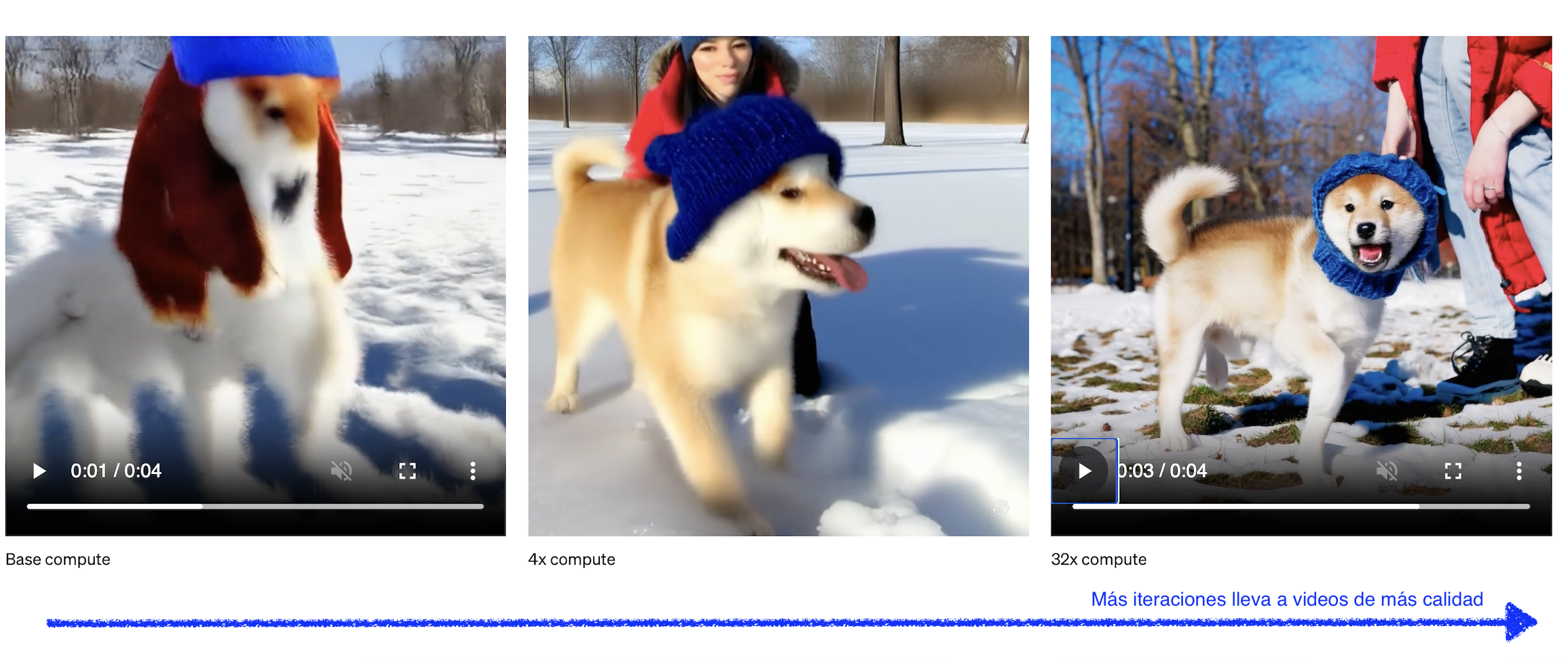
La próxima vez que generes una imágen y se demore, ya sabés que se debe a que se está limpiando el ruido en un proceso iterativo de la imágen ;)
El copilot del prompting
Para el que usó la primer versión de DALLE3, pudo haber notado que si uno escribía: un robot surfeando, la IA nos lo reescribía literalmente como: A robot surfing on a wave, displaying a dynamic balance and agility. The robot is designed with sleek, metallic surfaces reflecting the sunlight...
Es decir que ya no nos teniamos que preocupar de agregar tantos detalles de la imágen para que salierea con la calidad esperada del usuario promedio. Este avance de prompting copilot fue realmente muy novedoso, y es tambien una de las técnicas que se utilizan en Sora.
¿Te interesa protagonizar en el mundo de los datos e IA? Mira el programa de nuestro Bootcamp Data Analysis, Bootcamp Data Engineer y Bootcamp Data Science.
Difusión sin conducción, un sin sentido
El otro desafío para Sora es relacionar un prompt a una imagen. Esto ya se resolvió, y si bien no lo menciona directamente, deben estar utilizando un modelo como CLIP (también de OpenAI).
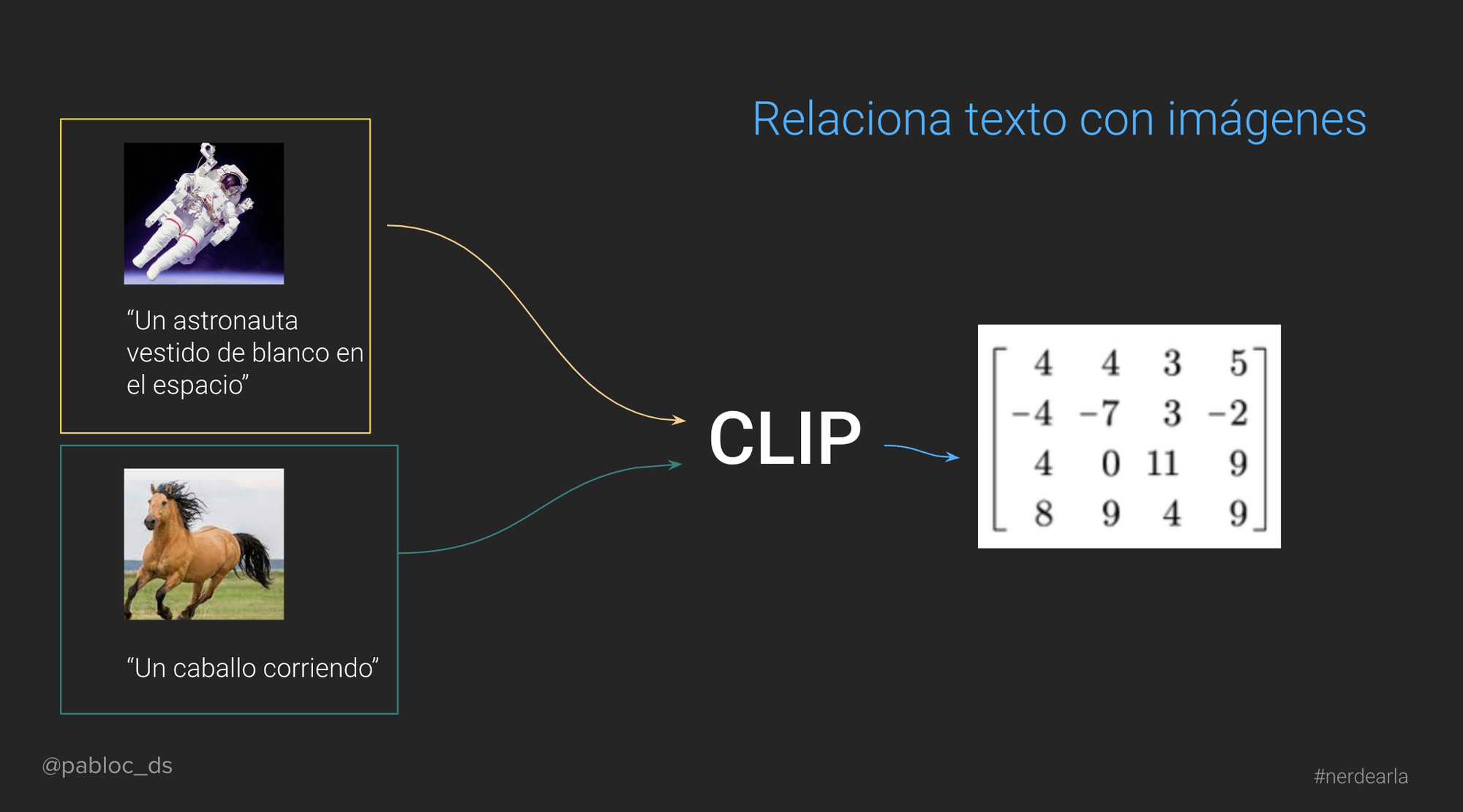
Modelos como CLIP permiten de forma automática, extraer características de una imágen como "espacio" y "astronauta" y relacionarlo a conceptos como "color negro" y "traje blanco".
El funcionamiento del mismo excede este post, pero al final les dejaré al final una charla que dí explicando estos puntos más técnicos sobre generación de imágenes en #Nerdearla: "Cómo funciona DALLE, la Inteligencia Artificial creativa", dónde al final mostraba el futuro: los primeros clips de video por IA.
Un paréntesis para el ingrediente secreto de Sora
En modelos como ChatGPT, la predicción es token a token, es decir, son partes de palabras que se predice una a una en base a las anteriores.
Por eso la frase "Te contamos de Sora en Escuela de Datos Vivos!" se convierte en 14 tokens:

Y simplificando 1 token en 1 palabra, se ve como cada una tiene una probabilidad de ser elegida:

El secreto de Sora: presentación de "patches" 💥
En Sora cada token representa un conjunto de imágenes y es interesante que sea un conjunto y no un frame como se usa comúnmente.
Este conjunto de imágenes lo denominaron patches.
Es decir pasamos de modelos que aprender a interpolar frames para luego hacer predicciones:

A modelos como Sora que ve "fragmentos" de película como si fuerea un solo frame. Acá el hardware es un punto crítico ya que si bien en el artículo mencionan la escalabilidad que les da la arquitectura de transformes, entrenar estos modelos.
👉 Este punto para mi, representa uno de los ingredientes secretos de esta consistencia temporal, algo que no vi nunca antes, y permite generar imágenes con cámaras como en el cine y con movimiento:
Seguramente se utilizaro otras tecnicas o hacks novedosos que no mencionaron aún, pero que te iremos contando ni bien se publique más información al respecto.
¿Dónde puede usar Sora?
Todavía no lo anunciaron, pero como siempre lo anunciaremos en redes sociales y newsletter de Escuela de Datos Vivos.
¿Cuánto costó entrenar a Sora? 💸
No lo sé, pero mucho.
Vamos a interpolar. El costo de entrenamiento del modelo similar a ChatGPT como el liberado por Meta, LLaMA2, asciende a 5 millones de dólares.
¿Cuánto podría haber costado entrenar este modelo? Al menos 20x o 30x, salvo que se haya encontrado una técnica novedosa de reducción de procesamiento.
Les dejo una regla de costos en entrenamiento de IA:
Procesar texto < Procesar imágenes < Procesar video
Es clave la relación OpenAI-Microsoft que hicieron para proveerles el hardware necesario. Hoy Microsoft es un actor clave en IA y por eso con Escuela de Datos Vivos estamos dentro del Microsoft Founder Hub, desarrollando productos de IA. Más de esto proximamente 😎
Conclusiones: Wow.
Lo que me hace pensar del surgimiento de esta tecnología es, como va a cambiar nuestro día a día. Hoy no podemos imaginar estudiar sin internet, programar sin ChatGPT.
Próximamente no nos imaginaremos el cine, los video-juegos y los servicios de streaming, sin inteligencias artificiales como Sora.
¿Te gusto el post? Compártelo con tus amigos y colegas!
Elige tu propia data aventura! 👩💻
Links adicionales: