
Este es un post sobre la selección de características usando algoritmos genéticos en R, en el que haremos una rápida revisión sobre:
- ¿Qué son los algoritmos genéticos (GA)?
- ¿GA en ML?
- ¿Cómo es una solución?
- El proceso de GA y sus operadores
- La función fitness o de aptitud
- Algoritmos genéticos en R!
- Inténtelo tú mismo.
- Relacionando conceptos
Fuente de la animación: "Locomoción muscular flexible para criaturas bípedas" - Thomas Geijtenbeek
La intuición detrás
Imaginemos una caja negra que puede ayudarnos a decidir sobre un número ilimitado de posibilidades, con un criterio tal que podamos encontrar una solución aceptable (tanto en tiempo como en calidad) a un problema que formulamos.
¿Qué son los algoritmos genéticos?
Los algoritmos genéticos (GA) son un modelo matemático inspirado en la famosa idea de Charles Darwin sobre la selección natural.
La selección natural preserva sólo a los individuos más aptos a lo largo de las diferentes generaciones.
Imagina una población de 100 conejos en 1900, si miramos la población actual, vamos a otros conejos más rápidos y hábiles para encontrar comida que sus antepasados.
Algoritmos Genéticos en Machine Learning
En machine learning, uno de los usos de los algoritmos genéticos es recoger el número correcto de variables para crear un modelo predictivo.
Recoger el subconjunto correcto de variables es un problema de combinatoria y optimización.
La ventaja de esta técnica sobre otras es que permite que la mejor solución surja de la mejor de las soluciones anteriores. Un algoritmo evolutivo que mejora la selección a lo largo del tiempo.
La idea de GA es combinar las diferentes soluciones generación tras generación para extraer los mejores genes (variables) de cada una de ellas. De esa manera crea nuevos y más adecuados individuos.
Podemos encontrar otros usos de GA es el caso de hyper-tuning parameter (tema que vemos en el curso Ciencia de Datos 360), encontrar el máximo (o mínimo) de una función o la búsqueda de una arquitectura de red neuronal correcta (Neuroevolución), entre otros...
GA en la selección de los artículos...
Cada posible solución de la GA, que son las variables seleccionadas (una sola 🐇), se consideran como un todo, no clasificará las variables individualmente contra el objetivo.
Y esto es importante porque ya sabemos que las variables trabajan en grupo.
¿Cómo es una solución?
Manteniéndolo simple para el ejemplo, imaginemos que tenemos un total de 6 variables,
Una solución puede ser recoger 3 variables, digamos: var2, var4 y var5.
Otra solución puede ser: var1 y var5.
Estas soluciones son los llamados individuos o cromosomas en una población. Son posibles soluciones a nuestro problema.

Crédito de la imagen: Vijini Mallawaarachchi
A partir de la imagen, la solución 3 puede ser expresada como un vector de un punto: c(1,0,1,0,1,1). Cada 1 indica la solución que contiene esa variable. En este caso: var1, var3, var5, var6.
Mientras que la solución 4 es: c(1,1,0,1,1,0).
Cada posición en el vector es un gen.
El proceso GA y sus operadores

La idea subyacente de un GA es generar algunas soluciones posibles aleatorias (llamadas population), que representan diferentes variables, para luego combinar las mejores soluciones en un proceso iterativo.
Esta combinación sigue las operaciones básicas de la GA, que son: selección, mutación y cross-over.
- Selección: Recoger los individuos más aptos en una generación (es decir: las soluciones que proporcionan el mayor ROC).
- Cross-over: Crear 2 nuevos individuos, basados en los genes de dos soluciones. Estos niños aparecerán a la siguiente generación.
- Mutación: Cambiar un gen de forma aleatoria en el individuo (es decir: cambiar un
0a1).
La idea es que para cada generación, encontraremos mejores individuos, como un conejo rápido.
Recomiendo el post de Vijini Mallawaarachchi sobre cómo funciona un algoritmo genético.
Estas operaciones básicas permiten al algoritmo cambiar las posibles soluciones combinándolas de manera que maximice el objetivo.
La función fitness (o función de aptitud)
Esta maximización del objetivo es, por ejemplo, para mantener la solución que maximiza el área bajo la curva ROC. Esto se define en la función fitness o de adecuación.
La función de adecuación toma una posible solución (o cromosoma, si se quiere parecer más sofisticada), y de alguna manera evalúa la eficacia de la selección.
Normalmente, la función de aptitud toma el vector de un punto c(1,1,0,0,0,0), crea, por ejemplo, un modelo random forest con var1 y var2, y devuelve el valor de aptitud (ROC).
El valor de aptitud en este código calcula es: ROC value / number of variables. Al hacer esto, el algoritmo penaliza las soluciones con un gran número de variables. Similar a la idea del criterio de información de Akaike, o AIC.

Algoritmos genéticos en R! 🐛
Mi intención es proporcionarle un código limpio para que puedas entender lo que hay detrás, y al mismo tiempo, probar nuevos enfoques como la modificación de la función de fitness. Este es un punto crucial.
Para usar en tu propio conjunto de datos, asegurarse que
data_x (data frames) y data_y (factor) sean compatibles con la función custom_fitness.
La librería principal es GA, desarrollada por Luca Scrucca. Ver aquí la viñeta con ejemplos.
📣 Importante: El siguiente código está incompleto. Clonar el repositorio para ejecutar el ejemplo.
# data_x: input data frame
# data_y: target variable (factor)
# GA parameters
param_nBits=ncol(data_x)
col_names=colnames(data_x)
# Executing the GA
ga_GA_1 = ga(fitness = function(vars) custom_fitness(vars = vars,
data_x = data_x,
data_y = data_y,
p_sampling = 0.7), # custom fitness function
type = "binary", # optimization data type
crossover=gabin_uCrossover, # cross-over method
elitism = 3, # best N indiv. to pass to next iteration
pmutation = 0.03, # mutation rate prob
popSize = 50, # the number of indivduals/solutions
nBits = param_nBits, # total number of variables
names=col_names, # variable name
run=5, # max iter without improvement (stopping criteria)
maxiter = 50, # total runs or generations
monitor=plot, # plot the result at each iteration
keepBest = TRUE, # keep the best solution at the end
parallel = T, # allow parallel procesing
seed=84211 # for reproducibility purposes
)
# Checking the results
summary(ga_GA_1)
── Genetic Algorithm ───────────────────
GA settings:
Type = binary
Population size = 50
Number of generations = 50
Elitism = 3
Crossover probability = 0.8
Mutation probability = 0.03
GA results:
Iterations = 17
Fitness function value = 0.2477393
Solution =
radius_mean texture_mean perimeter_mean area_mean smoothness_mean compactness_mean
[1,] 0 1 0 0 0 1
concavity_mean concave points_mean symmetry_mean fractal_dimension_mean ...
[1,] 0 0 0 0
symmetry_worst fractal_dimension_worst
[1,] 0 0
# Following line will return the variable names of the final and best solution
best_vars_ga=col_names[ga_GA_1@solution[1,]==1]
# Checking the variables of the best solution...
best_vars_ga
[1] "texture_mean" "compactness_mean" "area_worst" "concavity_worst"
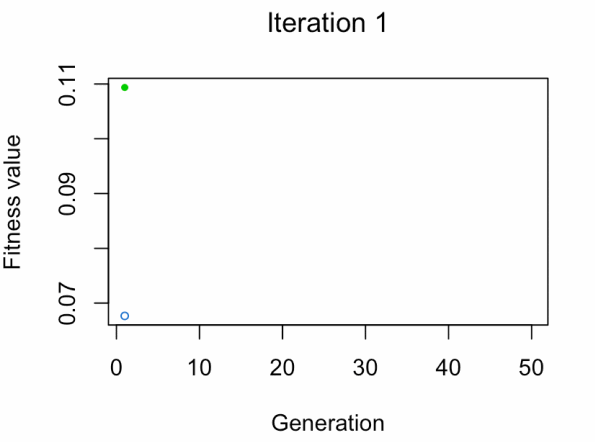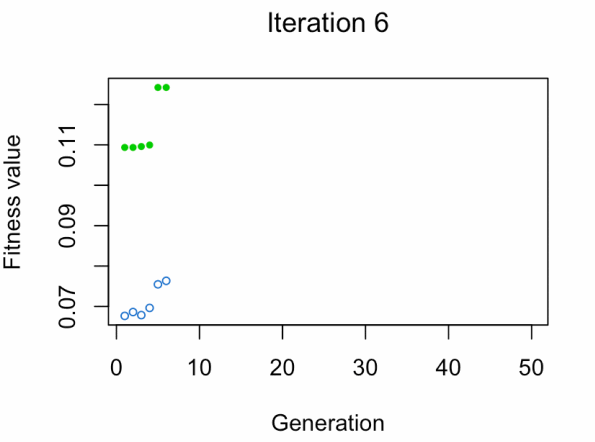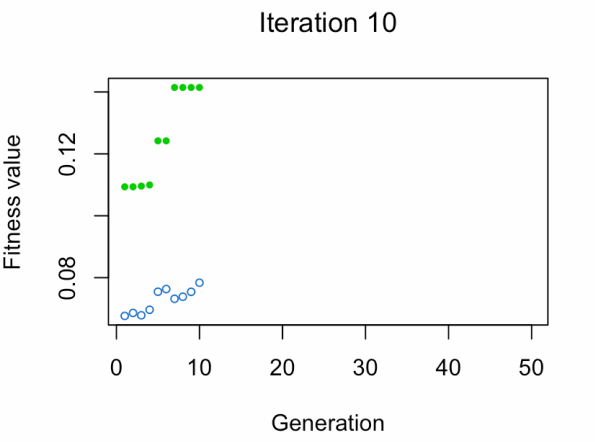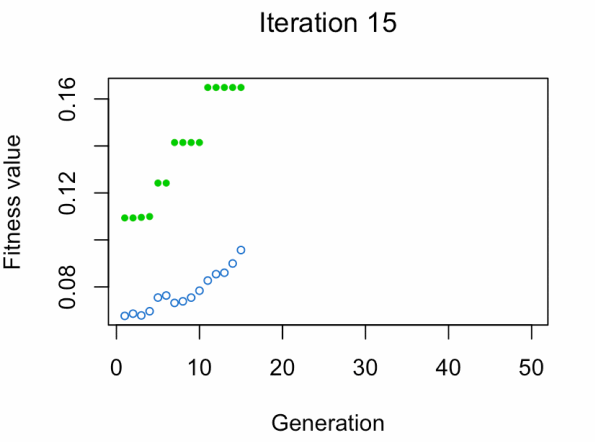
- Punto azul: Promedio de aptitud física de la población
- Punto verde: El mejor valor de aptitud física
Nota: No esperes el resultado tan rápido 😅
¡Ahora calculamos la precisión en base a la mejor selección!
get_accuracy_metric(data_tr_sample = data_x, target = data_y, best_vars_ga)
[1] 0.9508279
La precisión es de alrededor del 95,08%, mientras que el valor ROC está cerrado a 0,95 (ROC=valor de aptitud * número de variables, compruebe la función de aptitud).
Analizando los resultados
No me gusta analizar la precisión sin el punto de corte (Scoring Data), pero es útil para comparar con los resultados de este post de Kaggle.
Obtuvo un resultado de precisión similar usando la eliminación recursiva de características, o RFE, basado en 5 variables, mientras que nuestra solución se mantiene con 4.
Inténtelo usted mismo
Intenta una nueva función de fitness, algunas soluciones todavía proporcionan un gran número de variables, puedes intentar cuadrar el número de variables.
Otra cosa que se puede probar es el algoritmo para obtener el valor ROC, o incluso para cambiar la métrica.
Algunas configuraciones duran mucho tiempo. Equilibra las clases antes de modelar y juega con el parámetro
p_sampling. Las técnicas de muestreo pueden tener un gran impacto en los modelos. Revisa el tamaño de la muestra y el balance de clases en el post de rendimiento del modelo para más información.
¿Qué tal si cambiamos la tasa de mutación o elitismo? ¿O intentar otros métodos de cross-over?
Aumente el popsize para probar más soluciones posibles al mismo tiempo (con un coste de tiempo).
Siéntete libre de compartir cualquier idea o conocimiento para mejorar la selección.
Clonar el repositorio para ejecutar el ejemplo.
Relacionando conceptos
Hay un paralelismo entre los algoritmos genéticos y el deep learning, el concepto de iteración y mejora a lo largo del tiempo es similar.
Añadí el parámetro p_sampling para acelerar las cosas. Y generalmente logra su objetivo. Similar al concepto de lote (batch) usado en el deep learning. Otro paralelismo es entre el parámetro GA run y el criterio de parada temprana (o early stopper) en el entrenamiento de la red neural.
Pero la mayor similitud es que ambas técnicas provienen de la observación de la naturaleza. En ambos casos, los humanos observaron cómo funcionan las redes neuronales y la genética, y crean un modelo matemático simplificado que imita su comportamiento. La naturaleza tiene millones de años de evolución, ¿por qué no intentar imitarla? 🌱
---
Traté de ser breve sobre GA, pero si tienes alguna pregunta específica sobre este vasto tema, por favor déjala en los comentarios 🙋 🙋♂️
Gracias por leer 🚀
¿Quieres saber más? 📗 Libro vivo de ciencias de los datos
¿Te gustó el post? Compartilo con tus colegas amig@s y sumá un tema de conversación!