
Como este post recibió mas de 15k visitas en linkedin, lo hago permanente para que no se pierda en el tiempo.
Vistosa la imagen, pero -a mi criterio- habría que aclarar las excepciones 🤓.
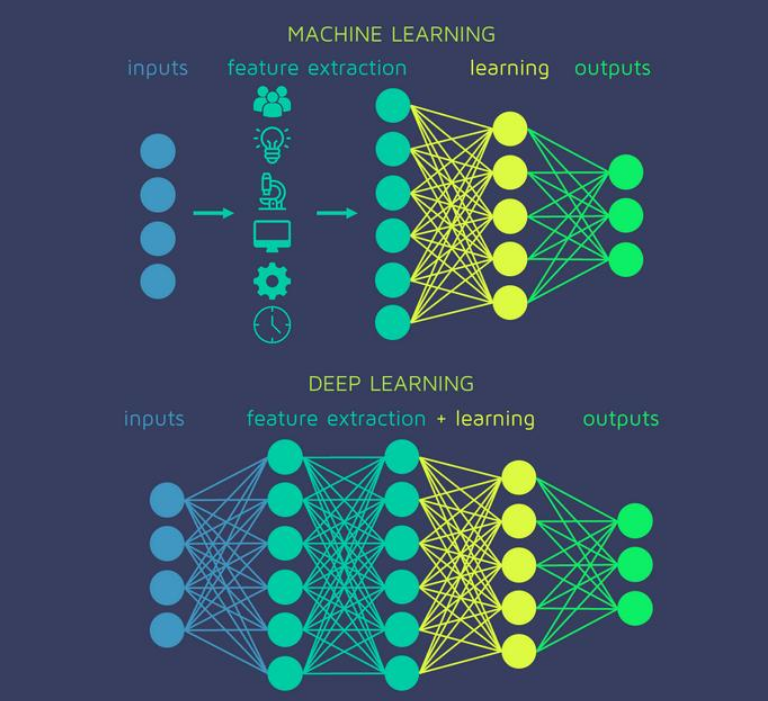
💡El feature extraction es encontrar nuevas variables que aporten información. En #deeplearning esto es automático, pero para imágenes. Por ejemplo, la red aprende sola a identificar curvas, rectas, texturas, hay varios posts al respecto como este.

El data scientist no le dice "que" formas/shapes aprender.
Ejemplo que también aplica a #NLP (no le indicamos la estructura semántica de las oraciones, la aprende).
💡Ahora en el enfoque de #ML, si tenemos que crear las features, por ejemplo tendencia en compras, última fecha con pico de presión arterial, etc.
Estos son los datos tabulares (1 fila 1 caso de estudio).
Acá un artículo de diferencia entre todas estas palabras de moda: ¿Cuál es la diferencia entre: Ciencia de Datos, Machine Learning, IA, Deep Learning y... Big Data?
Justamente es una de las partes de "Science", en "Data". No es automático, al menos por ahora 👩💻.