

Introducción
Muchas veces desarrollamos scripts que hacen cosas interesantes como analizar imágenes, hacer predicciones con modelos de ML, convertir audio en texto, etc.
Pero...
¿Qué ocurre si necesitamos que estos scripts funcionen las 24 horas del día, los 7 días de la semana?
¿O si queremos que nuestro script se ejecute cada N hs o N minutos?
¿O si simplemente queremos compartir nuestro script para que alguien lo ejecute desde una url?
Bueno, existen MUCHAS soluciones a este problema, pero en este articulo nos centraremos en una herramienta super sencilla que provee Google Cloud Platform (en adelante se usara la sigla GCP como referencia).
Esta herramienta son las Cloud Functions.
Cloud Functions es un entorno de ejecución que permite crear y conectar servicios en la nube, sin tener que provisionar ninguna infraestructura ni preocuparse por administrar ningún servidor.
Aca dejo un video de 1 min explicando con más detalle las Cloud Functions:
Objetivos
El objetivo de este articulo sera detallar el proceso para crear una Cloud Function en GCP, que se ejecute todos los días de manera automática y luego envíe la informacion procesada a un data warehouse llamado Google BigQuery.
Nota: la lectura de este post requiere una cierta autonomía trabajando en proyectos con python, ya que se da por sabido que el lector conoce minimamente como trabajar con varios archivos.py, utilizar la terminal, armar un requirements.txt, leer e interpretar código.
Agenda de Temas
- Crear una cuenta en GCP
- Crear un nuevo proyecto en GCP
- Crear un script de python que solicite el precio del dolar cada N minutos.
- Deploying Cloud Function con Cloud SDK
- Ejecutar la Cloud Function cada N minutos con Cloud Scheduler.
Crear una cuenta en GCP
Primero se debe ir al sitio de Google Cloud Platform.
Una una vez dentro, se mostrara la siguiente pantalla, donde haremos click en el boton "try it free":
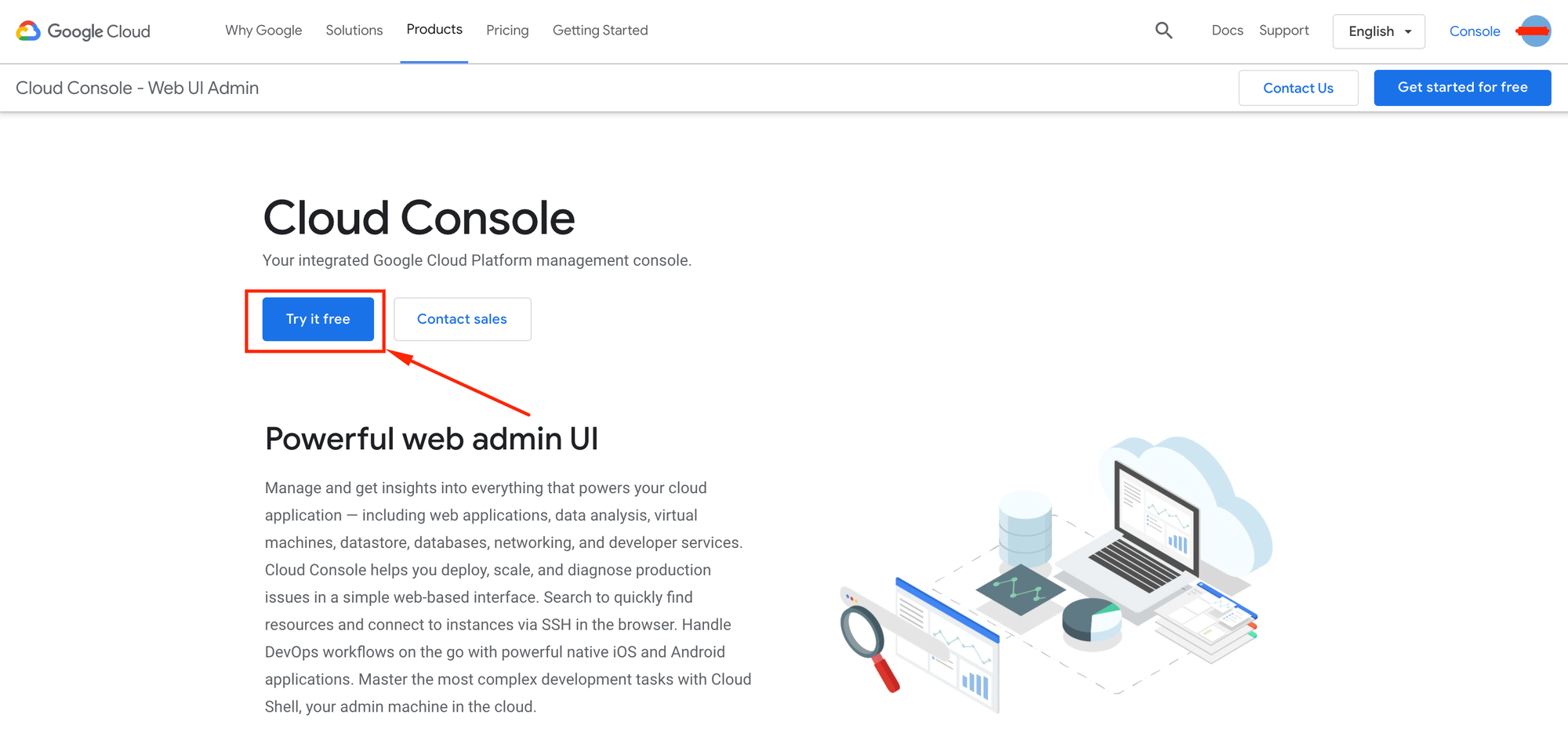
En la siguiente pantalla, aceptamos los términos y condiciones y luego hacemos click en continuar.
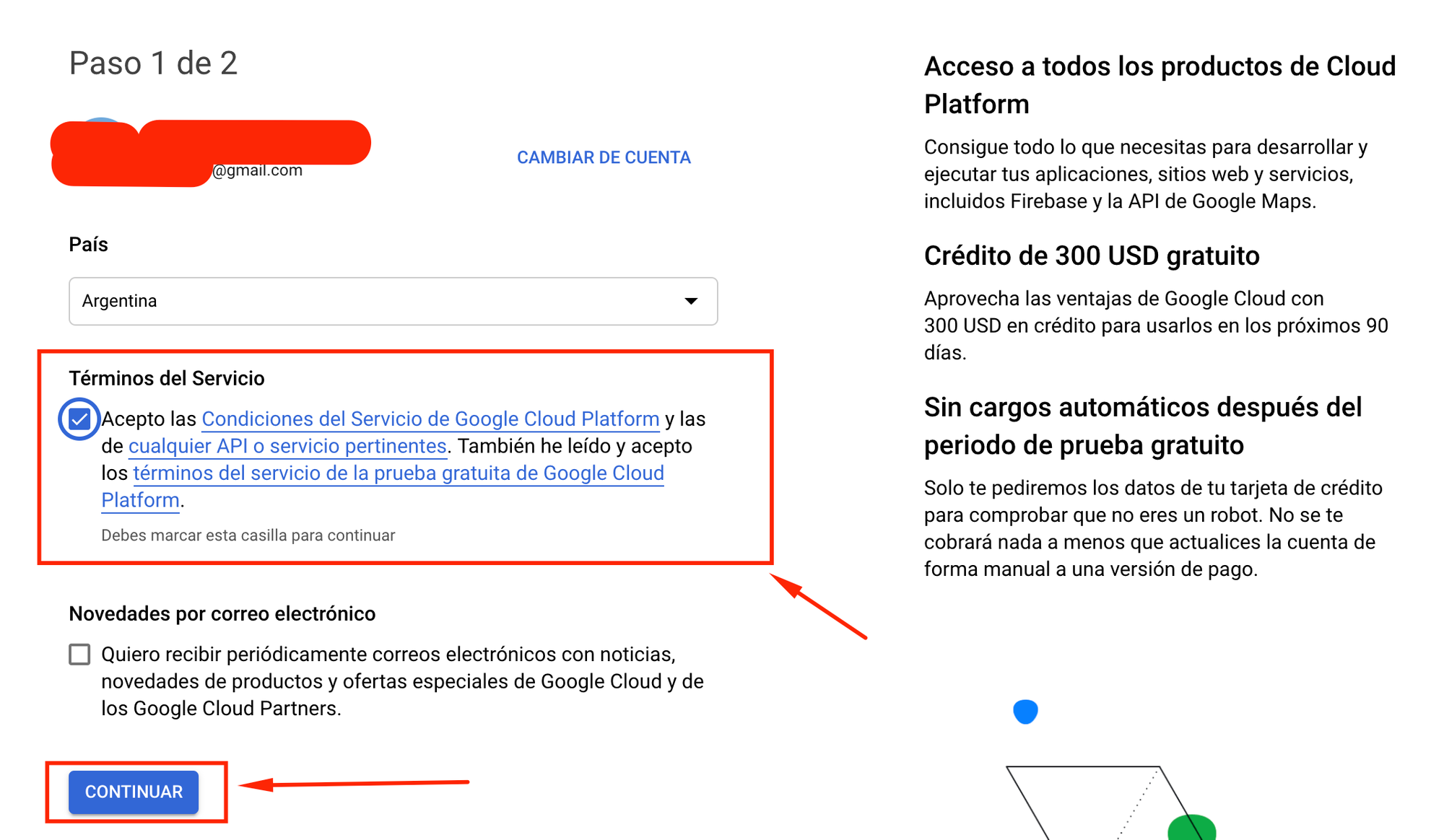
Aqui algo importante para remarcar:
Google otorga 300 dolares para que puedas aprovechar su plataforma de manera gratuita por 90 días. Pasados esos 90 días, se cobrara mensualmente el monto correspondiente a los servicios que se encuentren ejecutandose en ese momento.
Si bien los servicios de Google suelen ser baratos, es importante aclarar esto.
Por ejemplo, para una cloud function, las primeras 2 millones de ejecuciones son gratuitas, y luego se cobra $0.0000004 dolares por cada ejecucion.
En este link hay mas información sobre el pricing de una cloud function.
Continuando con la creación de la cuenta en GCP, en el paso final se pedirán los datos de una tarjeta de credito para poder iniciar la versión gratuita (no te van a cobrar nada hasta pasados los 90 dias):
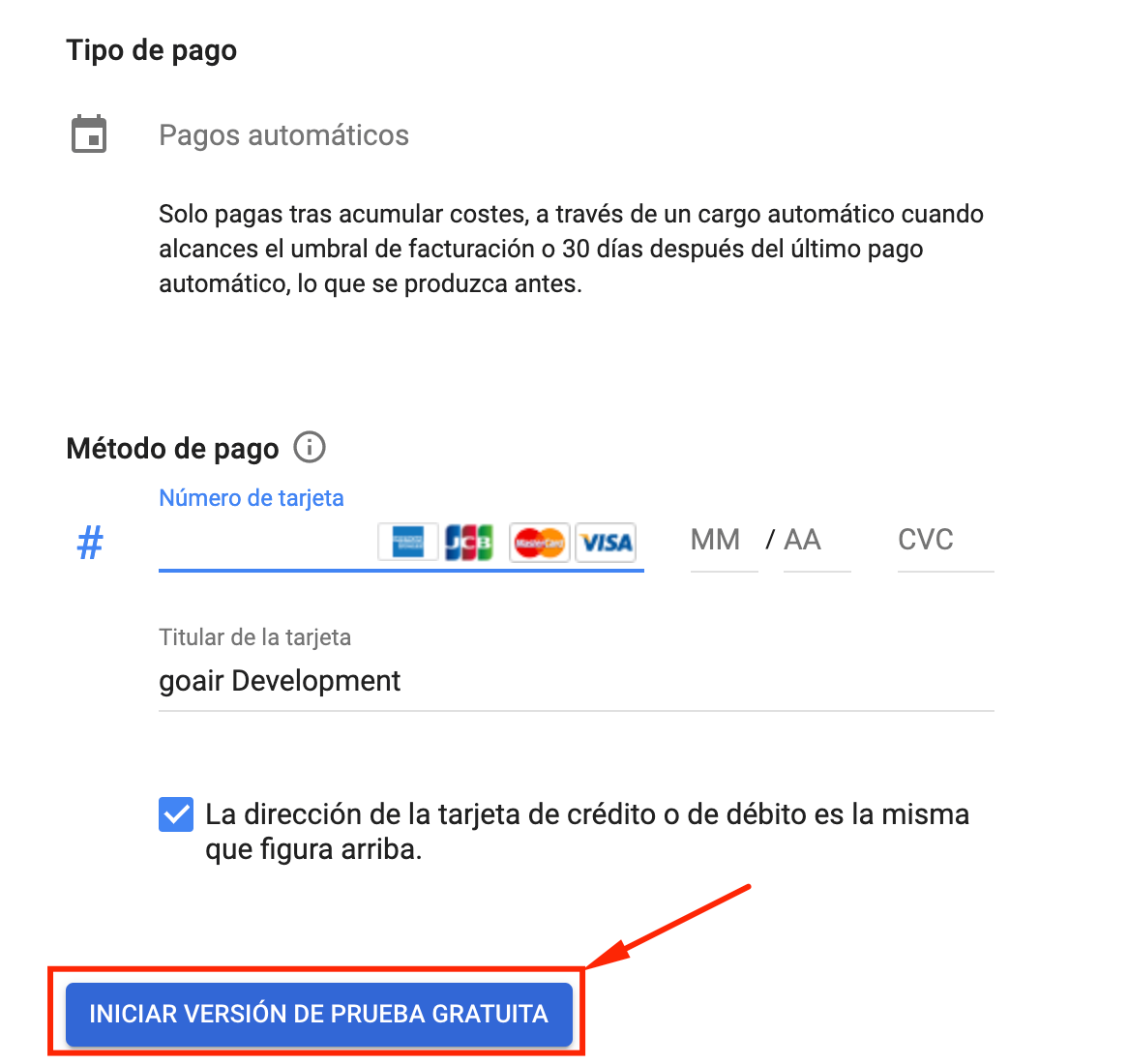
En este punto ya deberías tener tu cuenta de GCP creada! Asi que es momento de iniciar un nuevo proyecto.
Crear nuevo proyecto en GCP
Crear un nuevo proyecto en GCP es muy sencillo. Se debe ir a este link, poner un nombre al proyecto y hacer click en create:
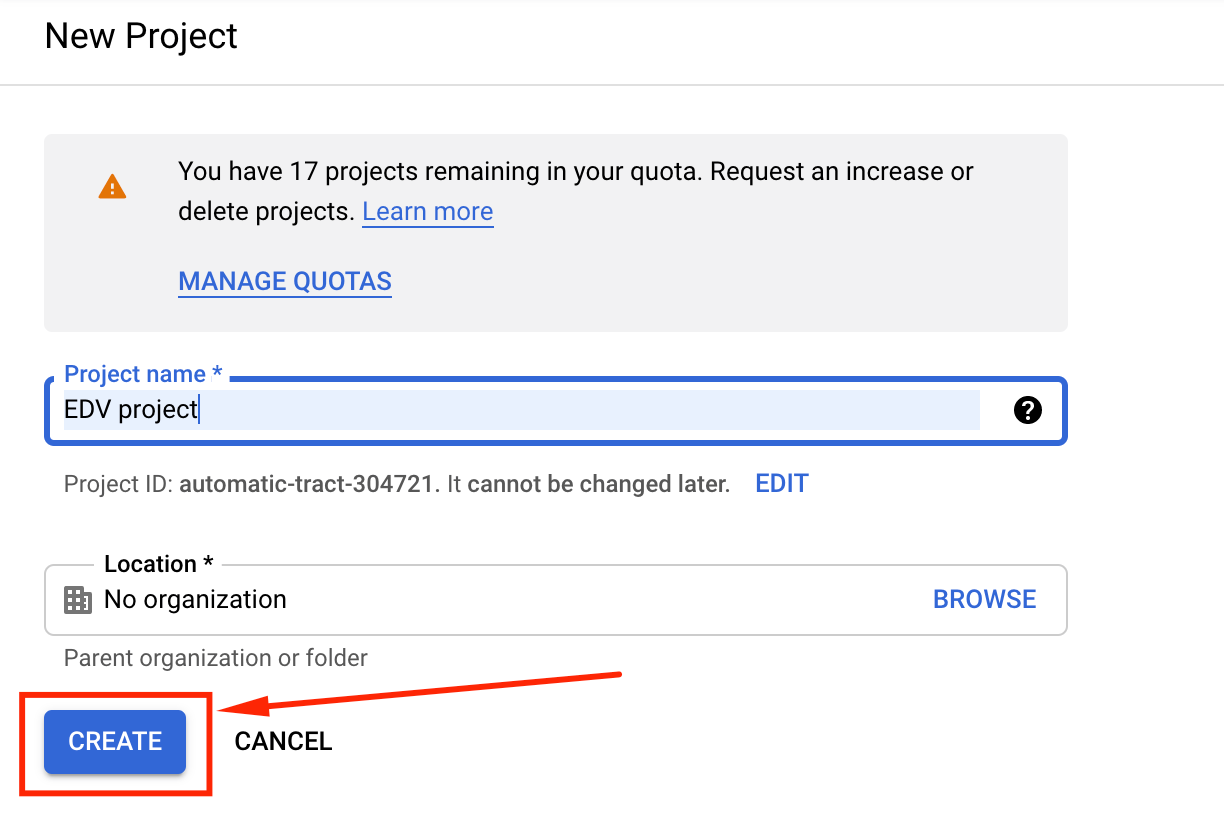
Luego de crear el proyecto, el sitio nos redirige al Dashboard del mismo, en el cual se detallan todos los recursos que se están usando, el precio en dólares que se cobrará a fin de mes ($0.00 en este caso), información general del proyecto, etc.
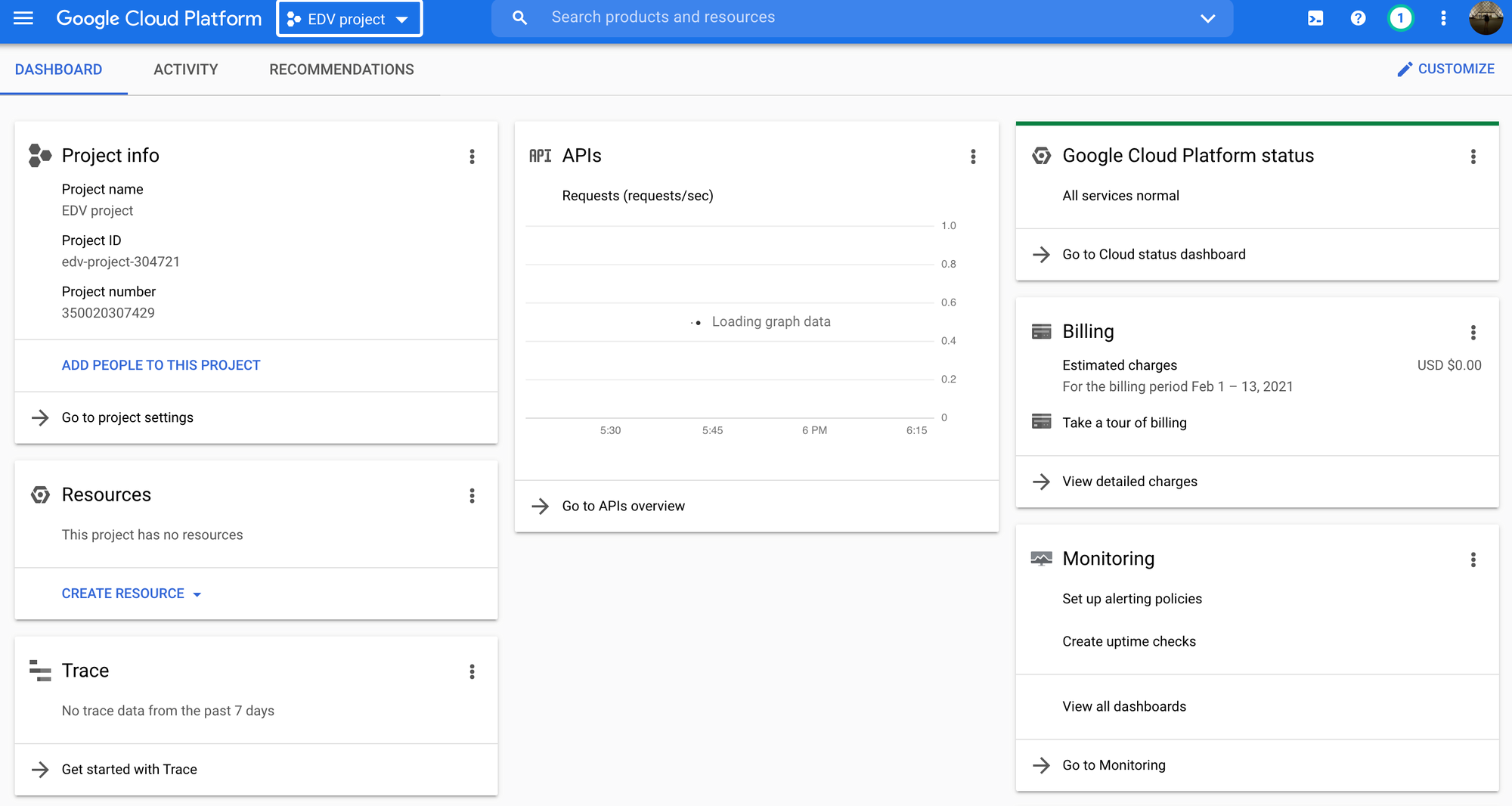
En la parte lateral izquierda podemos ver un cuadro titulado "Project info", el cual contiene el campo Project ID. Debemos anotar este valor ya que luego sera necesario. En este caso tenemos:
Project ID: edv-project-304721
Como en este proyecto se trabajara con Google BigQuery, sera necesario activar su correspondiente API.
Para los que no entiendan que es una API, básicamente sirve para que dos aplicaciones de software se puedan comunicar.
Por ej:
Supongamos que un script de Python quiere comunicarse con Google Maps.
Para que esto sea posible, Google Maps tiene su propia API.
Esta API establece 2 cosas fundamentales:
- Como se debe pedir la información
- Como sera la respuesta resultante ante esa petición.
Entonces, volviendo a lo nuestro... En el buscador que se encuentra en la parte superior del Dashboard del proyecto, buscamos BigQuery API:

Luego hacemos click en enable (en este caso aparece manage porque ya se encuentra activada la API):
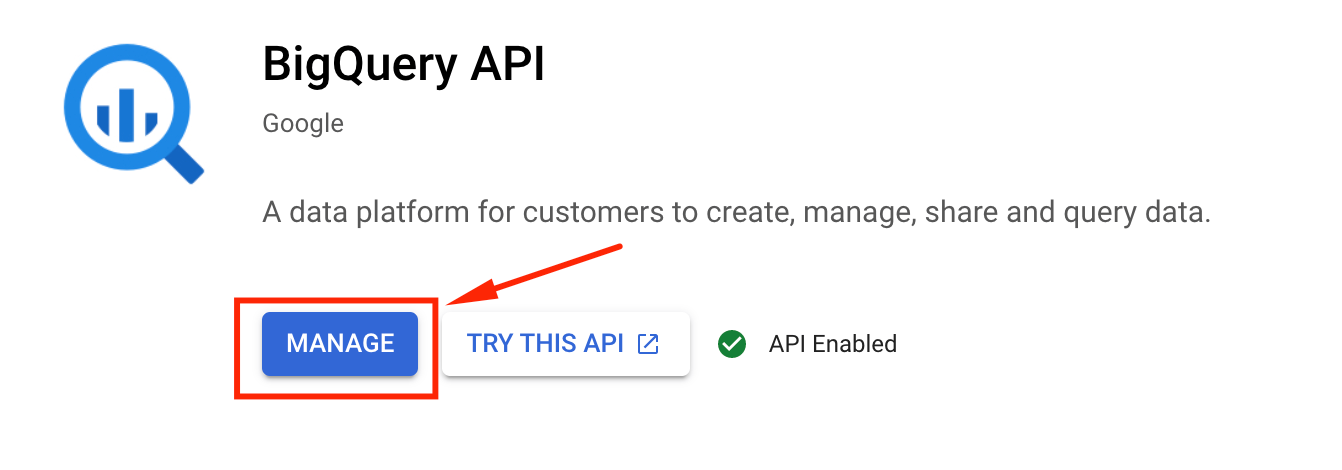
Una vez activada la API de Google BigQuery, podemos crear un nuevo dataset.
En BigQuery, un dataset es como un contenedor que permite organizar nuestras tablas y vistas, por lo cual un mismo dataset puede alojar muchas tablas y muchas vistas (una vista es el resultado de una query a una tabla del dataset).
En el buscador del Dashboard de nuestro proyecto, buscamos BigQuery y hacemos click en el primer resultado que aparezca. Se debería visualizar la siguiente pantalla:
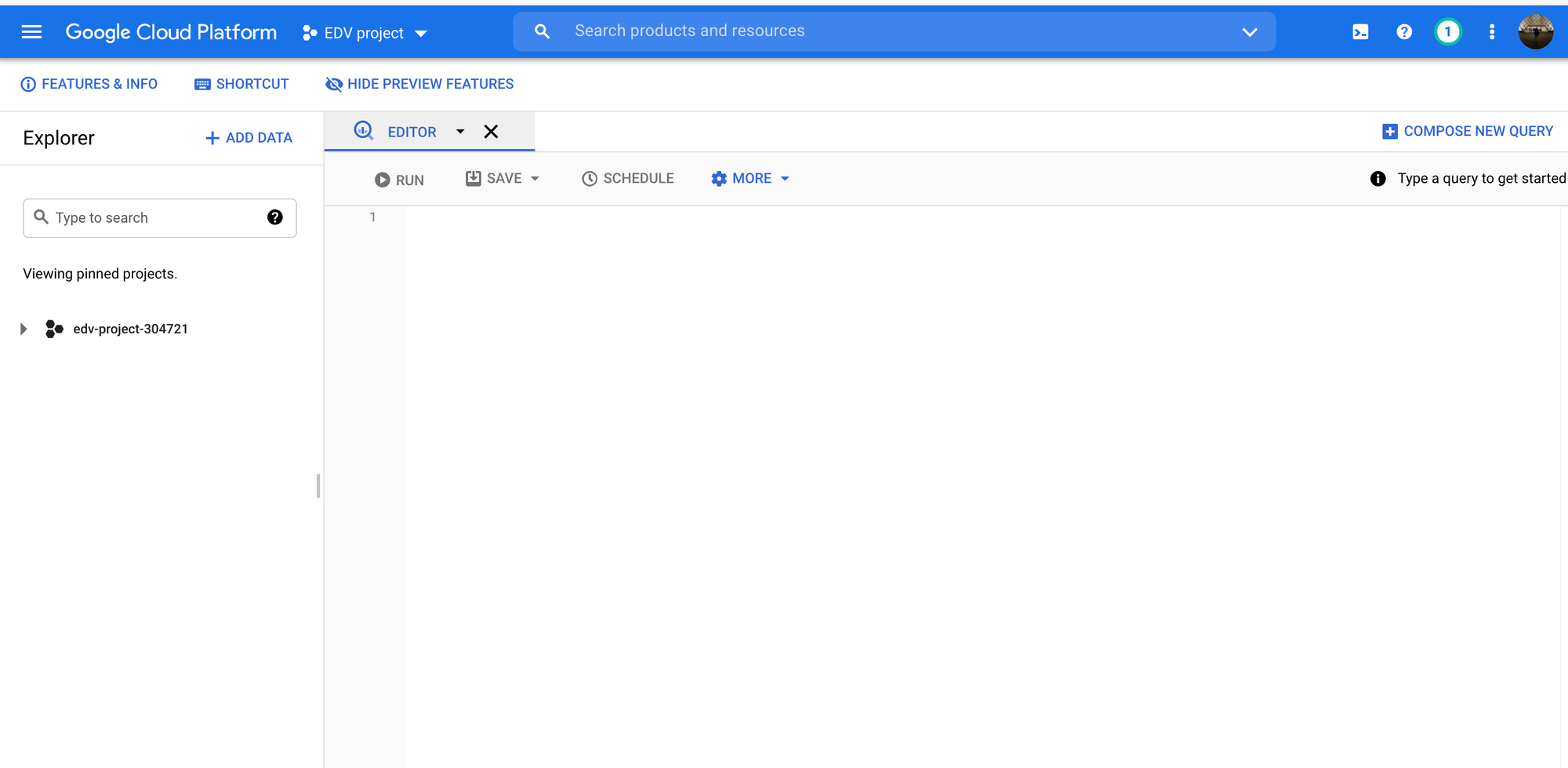
Tocamos los 3 puntos negros de la izquierda, donde se encuentra el ID del proyecto, y luego hacemos click en Create Dataset:
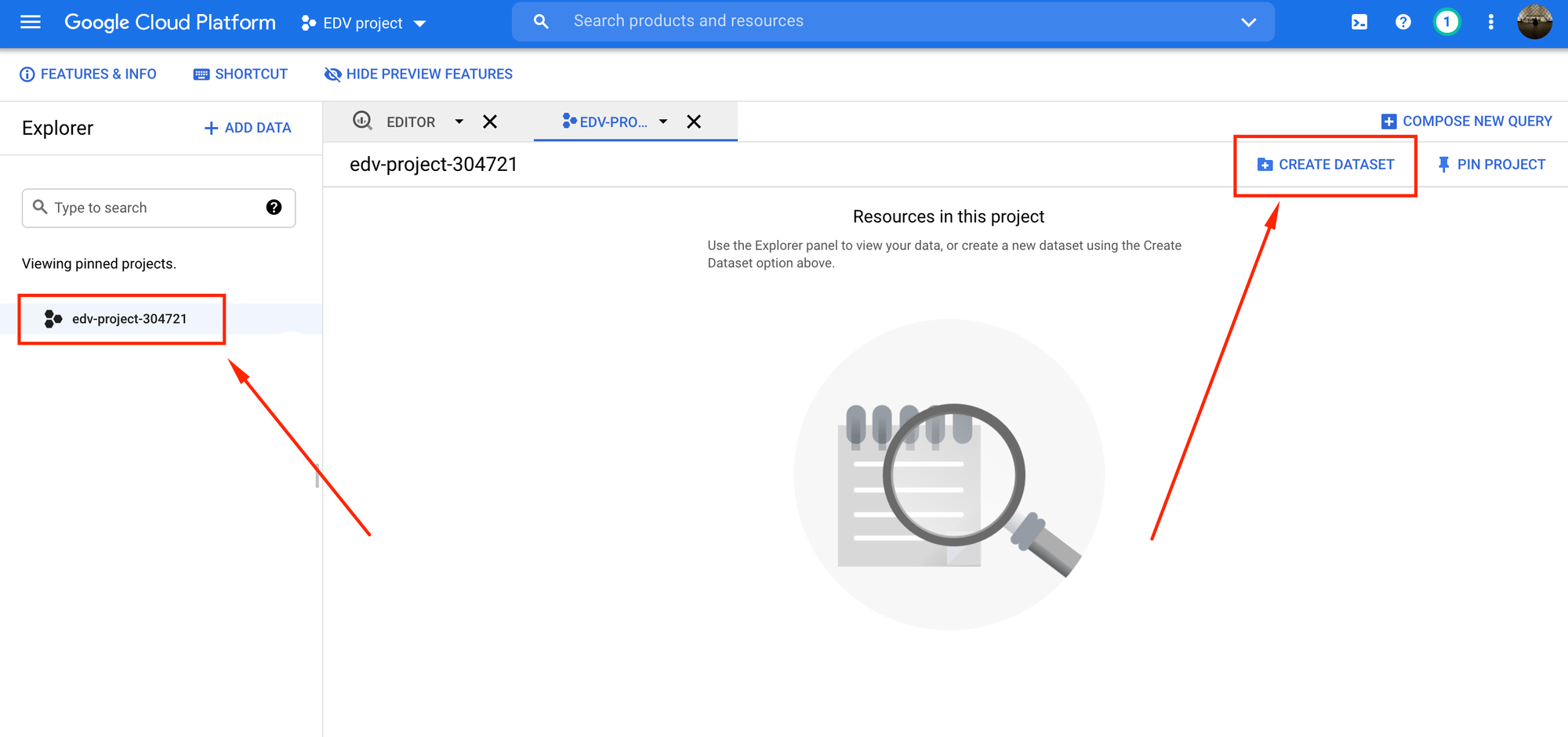
Se abrirá la siguiente ventana donde deberá poner un nombre para el dataset.
En este caso:
edv_dataset
Finalmente hacemos click en create:
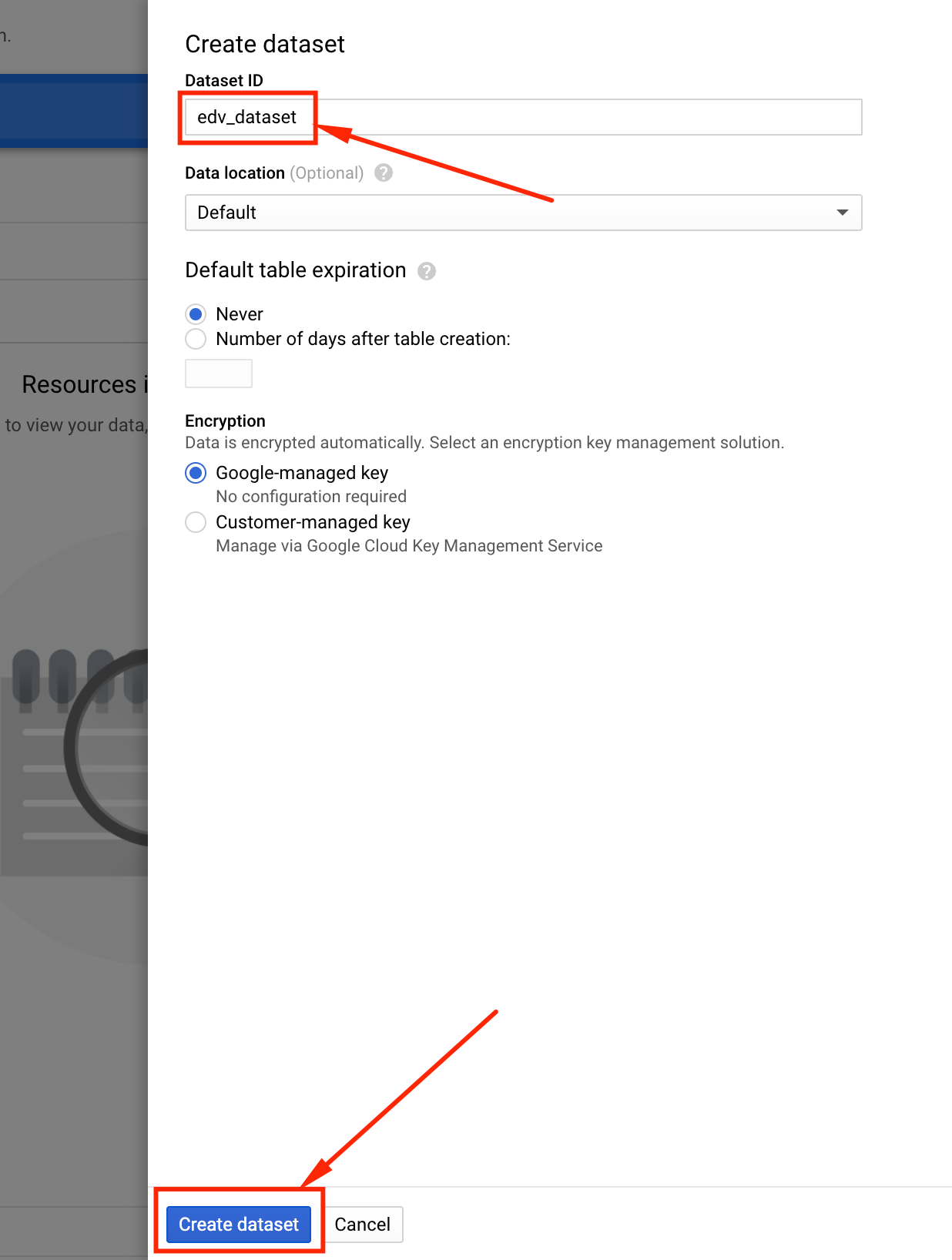
A partir de este punto tendremos creado un nuevo dataset en Google BigQuery.
Mas adelante crearemos una tabla dentro de este dataset, la cual almacenara la información procesada por la Cloud Function.
Script: solicitar el precio del dolar cada N minutos
Antes de arrancar, pueden descargar todo el código del proyecto desde el siguiente repositorio de GitHub.
Las dependencias a instalar son las siguientes:
pip install lxml
pip install requests
pip install pandas
pip install google-api-python-client
pip install google-cloud-bigquery
pip install pyarrowLa idea es hacer un request HTTP al sitio https://www.dolarhoy.com/ para obtener el precio de cada tipo de dólar:
- Dolar blue
- Dolar oficial
- Dolar bolsa
- Dolar contado con liquidacion
Para empezar, creamos una carpeta para el proyecto en cualquier ruta de nuestra pc.
Por ej: en Documents/Github/edv_project_gcpDentro de la carpeta del proyecto, se deben crear cuatro archivos .py, los cuales seran subidos mas tarde a GCP como una cloud function.
Estos archivos serán:
main.py
dolar_value.py
bigquery_uploader.py
schema.py
Dentro del archivo dolar_value.py creamos la funcion request_dolar_value:
import requests
from lxml.html import fromstring
from lxml.cssselect import CSSSelector
import pandas as pd
def request_dolar_value():
dolar_price_urls = [
'https://www.dolarhoy.com/cotizaciondolarblue',
'https://www.dolarhoy.com/cotizaciondolaroficial',
'https://www.dolarhoy.com/cotizaciondolarbolsa',
'https://www.dolarhoy.com/cotizaciondolarcontadoconliqui'
]
titleSelector = CSSSelector("div[class='topic']")
valueSelector = CSSSelector("div[class='value']")
dolar_value_column = [] # precio del dolar
dolar_type_column = [] # blue, oficial, bolsa o contado con liqui
dolar_topic_column = [] # compra o venta
for url in dolar_price_urls:
try:
r = requests.get(url)
html_tree = fromstring(r.text)
dolar_topic_column += [e.text for e in titleSelector(html_tree)] # compra o venta
dolar_value_column += [e.text.replace("$","") for e in valueSelector(html_tree)]
dolar_name = url.split("cotizaciondolar")[-1] # blue, bolsa.. etc
dolar_type_column += [dolar_name]*2
except Exception as e:
print(e)
continue
dolar_df = pd.DataFrame({
'dolar_type': dolar_type_column,
'topic': dolar_topic_column,
'dolar_value': dolar_value_column
})
dolar_df['dolar_value'] = dolar_df['dolar_value'].astype(float)
dolar_df['load_timestamp'] = pd.to_datetime('now') # UTC
return dolar_df
Si se ejecuta la funcion anterior, se obtiene el siguiente dataframe:
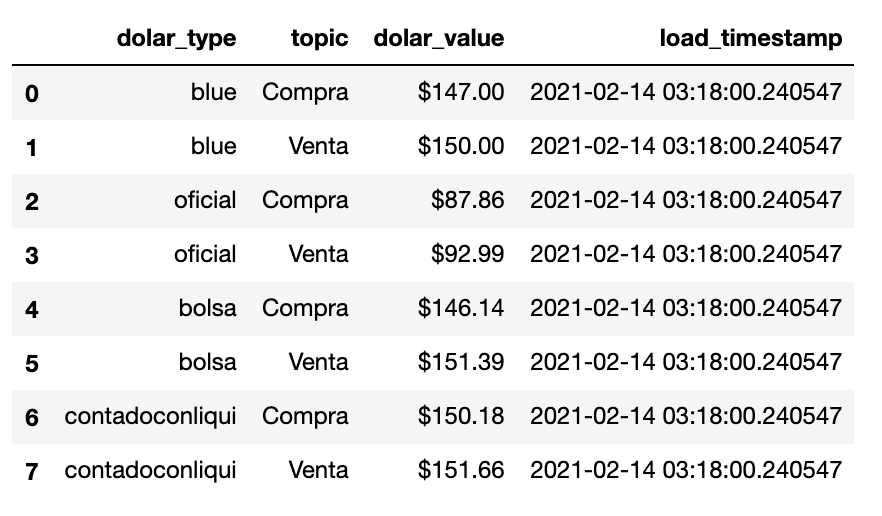
Dentro del archivo bigquery_uploader.py debemos escribir la funcion load_df_to_bigquery.
Esta funcion recibe 7 parametros:
- project_id(str): ID del proyecto creado en GCP.
- dataset_id (str): ID del dataset de Google BigQuery
- table_name (str): nombre de la tabla de Google BigQuery
- df(pandas): pandas daframe que se subira a BigQuery.
- schema(list of dicts): columnas del dataframe a subir.
- partition_field(str): columna que se usara como particion.
- append (bool): si toma valor True, se hara un append de los nuevos datos.
A continuación, el codigo que se debe poner dentro de bigquery_uploader.py:
from google.cloud import bigquery
def load_df_to_bigquery(project_id, dataset_id, table_name,
df, schema, partition_field, append=False):
'''
Load pandas df to a partitioned bigquery table.
If the table does not exists, it creates a partitioned table.
Args:
client(bigquery.Client): bigquery client.
project_id(str): ID of google cloud project.
dataset_id (str): ID of the database on Google Big Query.
table_name (str): name of the table to be updated or crated.
df(pandas): pandas df which will be uploaded.
schema(list of dicts): bigquery table schema in format [{},{}..{}]
partition_field(str): column to use as partition field
append (bool): if True, appends the new data. If False, replaces it.
Returns:
int: the http status code
'''
try:
# Init Big Query Client
print('Initializing GBQ Client..')
client = bigquery.Client(project=project_id)
print(
'\nUploading table {} to Google BigQuery.'.format(table_name)
)
# Get reference dataset
dataset_ref = client.dataset(dataset_id)
table_id = project_id+'.'+dataset_id+'.'+table_name
try:
# Check if table exists in reference dataset
bq_table = client.get_table(table_id)
except Exception:
print("Table {} doesn't exist. Creating it..".format(table_id))
# Create table reference
table_ref = dataset_ref.table(table_name)
# Set table schema
table = bigquery.Table(table_ref, schema=schema)
# Create partition by date
table.time_partitioning = bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field=partition_field,
)
# Create table
created_table = client.create_table(table)
print(
"Created table {}, partitioned on column {}".format(
created_table.table_id,
created_table.time_partitioning.field
)
)
# Get created table
bq_table = client.get_table(table_id)
# Load Job Config
job_config = bigquery.LoadJobConfig()
job_config.source_format = bigquery.SourceFormat.PARQUET
job_config.autodetect = True
# Append or replace data
if append is True:
job_config.write_disposition = bigquery.\
WriteDisposition.\
WRITE_APPEND
else:
job_config.write_disposition = bigquery.\
WriteDisposition.\
WRITE_TRUNCATE
# Load Pandas Dataframe to Bigquery
job = client.load_table_from_dataframe(
df,
bq_table,
job_config=job_config
)
# Waits for the job to complete.
job.result()
# show info
print("Successful! Loaded {} rows into {}:{}.".format(
job.output_rows,
dataset_id,
table_id)
)
return 200
except Exception as e:
print('[ERROR] {}'.format(e))
return 400En el archivo schema.py se debe escribir el schema de la tabla que se subira a Google BigQuery. En el schema se definen los nombres de cada columna y sus respectivos data types.
A continuacion el schema de nuestra tabla:
SCHEMA = [
{
"name": "dolar_type",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "topic",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "dolar_value",
"type": "FLOAT",
"mode": "NULLABLE",
},
{
"name": "load_timestamp",
"type": "TIMESTAMP",
"mode": "NULLABLE",
"description": "date on which the data was requested"
},
]Finalmente, dentro del archivo main.py se invocaran las funciones creadas en los archivos dolar_value.py, bigquery_uploader.py y el schema.py.
En el top de este archivo, se deben definir las siguientes variables globales:
BIGQUERY_PROJECT_ID = 'edv-project-304721' # poner el id del proyecto
BIGQUERY_DATASET_ID = 'edv_dataset' # poner el id del dataset de BigQuery
BIGQUERY_TABLE_NAME = 'dolar_evolution' # poner un nombre cualquier para la tabla
PARTITION_FIELD = 'load_timestamp' # no tocar
APPEND_DATA_ON_BIGQUERY = True # cambiar a False en caso de querer que los nuevos datos reemplacen los viejos datosFinalmente, el archivo main.py queda de la siguiente manera:
from bigquery_uploader import load_df_to_bigquery
from dolar_value import request_dolar_value
from schema import SCHEMA
def main(request):
try:
# PROJECT VARIABLES
BIGQUERY_PROJECT_ID = 'edv-project-304721'
BIGQUERY_DATASET_ID = 'edv_dataset'
BIGQUERY_TABLE_NAME = 'dolar_evolution'
PARTITION_FIELD = 'load_timestamp'
APPEND_DATA_ON_BIGQUERY = True
# Request dolar data
dolar_data = request_dolar_value()
# Check is the created dataframe is not empty
if dolar_data is None or len(dolar_data) == 0:
print('No content, table has 0 rows')
return ('No content, table has 0 rows', 204)
# Save on Google Big Query
print("saving data into Google Big Query....")
http_status = load_df_to_bigquery(
project_id=BIGQUERY_PROJECT_ID,
dataset_id=BIGQUERY_DATASET_ID,
table_name=BIGQUERY_TABLE_NAME,
df=dolar_data,
schema=SCHEMA,
partition_field=PARTITION_FIELD,
append=APPEND_DATA_ON_BIGQUERY
)
if http_status == 200:
return ('Successful!', http_status)
else:
return ("Error. Please check the logging pannel", http_status)
except Exception as e:
error_message = "Error uploading data: {}".format(e)
print('[ERROR] ' + error_message)
return (error_message, '400')
La funcion main recibe un parametro request que en este caso no se utiliza.
Ese parametro sirve en los casos en los que se necesite setear variables usando la URL de la cloud function.
Terminado el proyecto, podemos abrir la terminal y ejecutar en la misma ruta del proyecto el comando:
pip freeze> requirements.txt
Esto va crear un archivo llamado requirements.txt con las dependencias del proyecto. El archivo requirements.txt deberia contener la siguiente información:
cachetools==4.2.1
certifi==2020.12.5
cffi==1.14.5
chardet==4.0.0
google-api-core==1.26.0
google-api-python-client==1.12.8
google-auth==1.26.1
google-auth-httplib2==0.0.4
google-cloud-bigquery==2.8.0
google-cloud-core==1.6.0
google-crc32c==1.1.2
google-resumable-media==1.2.0
googleapis-common-protos==1.52.0
grpcio==1.35.0
httplib2==0.19.0
idna==2.10
lxml==4.6.2
numpy==1.20.1
packaging==20.9
pandas==1.2.2
proto-plus==1.13.0
protobuf==3.14.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pycparser==2.20
pyparsing==2.4.7
python-dateutil==2.8.1
pytz==2021.1
requests==2.25.1
rsa==4.7
six==1.15.0
uritemplate==3.0.1
urllib3==1.26.3
cssselect==1.1.0
pyarrow==3.0.0
Ahora si! ya podemos subir nuestro proyecto a GCP como una Cloud Function.
Deploy una Cloud Function con Cloud SDK
Para subir nuestro código a una cloud function usando la terminal, debemos instalar cloud sdk desde este link
El SDK de Cloud es un conjunto de herramientas que puedes usar para administrar recursos y aplicaciones alojados en Google Cloud.
Aquí dejo un excelente tutorial que muestra como instalar cloud SDK.
Una vez instalado cloud sdk, abrimos una terminal y nos movemos hacia la carpeta de nuestro proyecto. Una vez dentro de la carpeta sera necesario loguearse en cloud SDK usando el comando gcloud auth login:
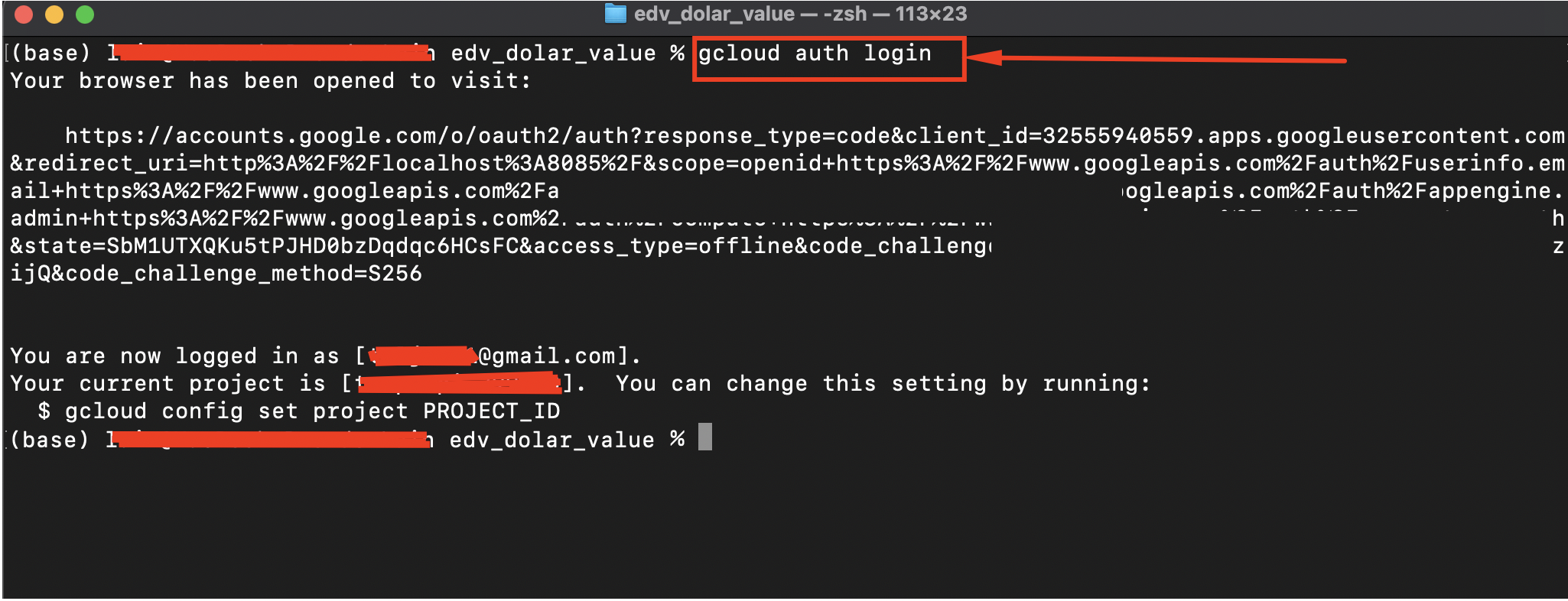
El comando anterior abrirá una url de autenticacion. Solo debe dar click en continuar hasta llegar a una pantalla de éxito.
Desde este punto ya estamos habilitados a hacer el deploy de nuestra cloud function.
Hacer el deploy es muy sencillo, solo debe ejecutar el comando gcloud functions deploy function_name con una serie de flags:
Los flags servirán para configurar nuestra cloud function. Los flags que usaremos son:
--project=edv-project-304721
--trigger-http
--timeout=540
--memory=512MB
--region=us-central1
--runtime=python38
--entry-point=main--project sirve para especificar en que proyecto se hara el deploy de la función.
--trigger-http indica el tipo trigger que ejecutara nuestra función. En este caso, la funcion se ejecuta cuando se abre una url especifica.
--timeout es el tiempo máximo de ejecución de la función (540 segundos es el limite maximo).
--memory es la memoria reservada.
--runtime indica el lenguaje en el cual esta escrito el codigo de la cloud function
--entry-point indica la función que deberá ejecutar la cloud function cuando se dispare el trigger. En nuestro, dentro del archivo main.py, se encuentra la función main, la cual se encarga ejecutar todo el código del proyecto. Por lo tanto, la función main sera nuestro entry point.
Si unimos todas los flags, el comando final que debemos ejecutar queda de la siguiente forma (dolar_evolution es el nombre de la cloud function):
gcloud functions deploy dolar_evolution --region=us-central1 --runtime=python38 --entry-point=main --memory=512MB --trigger-http --timeout=540 --project=edv-project-304721Una vez terminado el deploy, debería observar el siguiente mensaje en la terminal (versionId deberia ser 1 en caso de ser primer deploy).

Para ver nuestra cloud function, podemos ir al dashboard de nuestro proyecto y en el recuadro de recursos hacer click en 'cloud functions':
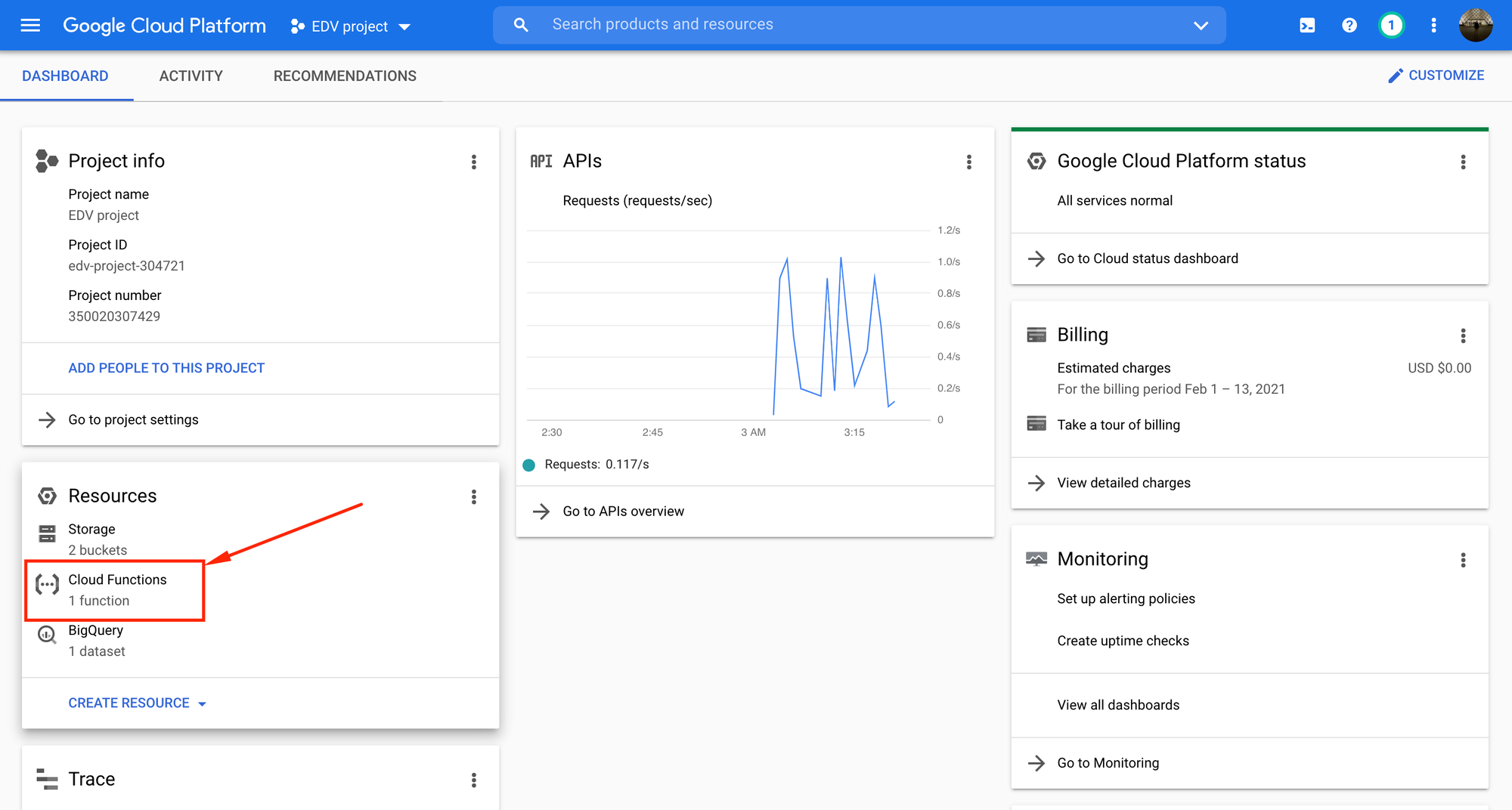
Aparecera la siguiente pantalla, donde se puede observar que el deploy se hizo correctamente:

Si hacemos click en el nombre de la cloud function, nos redirigira a una nueva pantalla con varias pestañas. Una de esas pestañas se llama trigger:
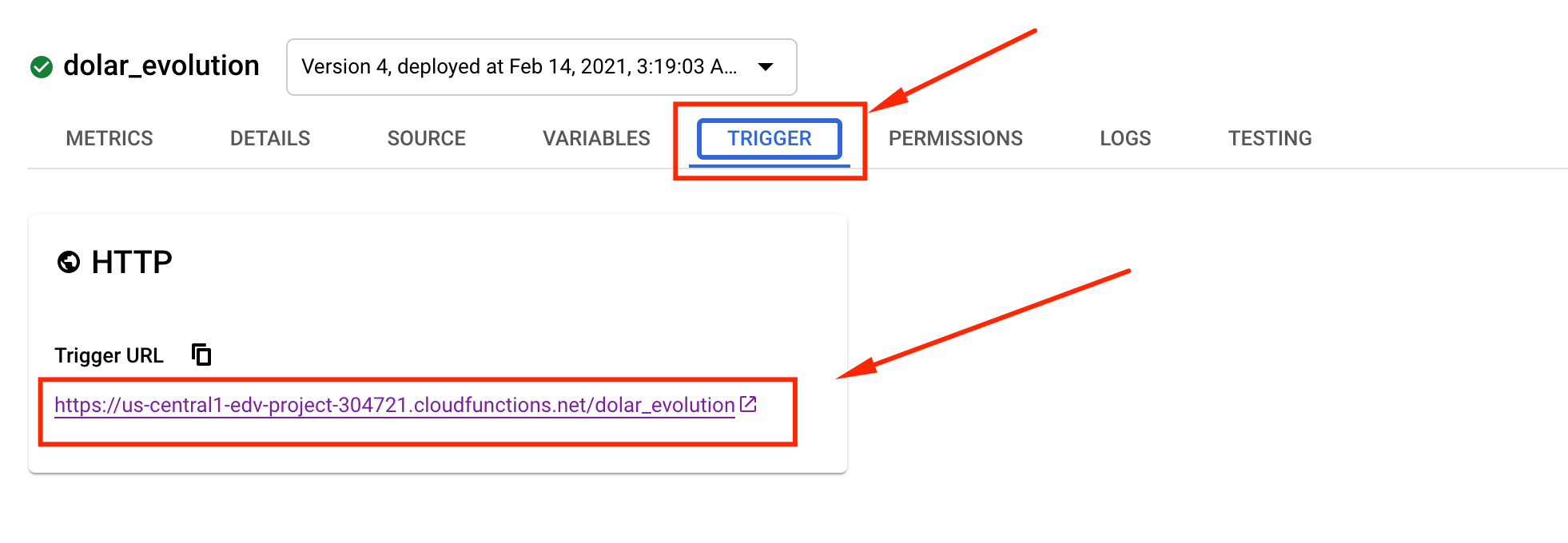
Dentro de esta pestaña podemos ver el trigger que ejecuta la cloud function.
Si hacemos click en él, nos redigira a la siguiente pantalla de advertencia, indicando que estamos saliendo de google. Para ejecutar la cloud function hacemos click en el link mas largo:

Si todo va bien, un mensaje de éxito debería aparecer en la pantalla 😃😃.

Para chequear la informacion, podemos ir Google BigQuery y desplegar el dataset que creamos:
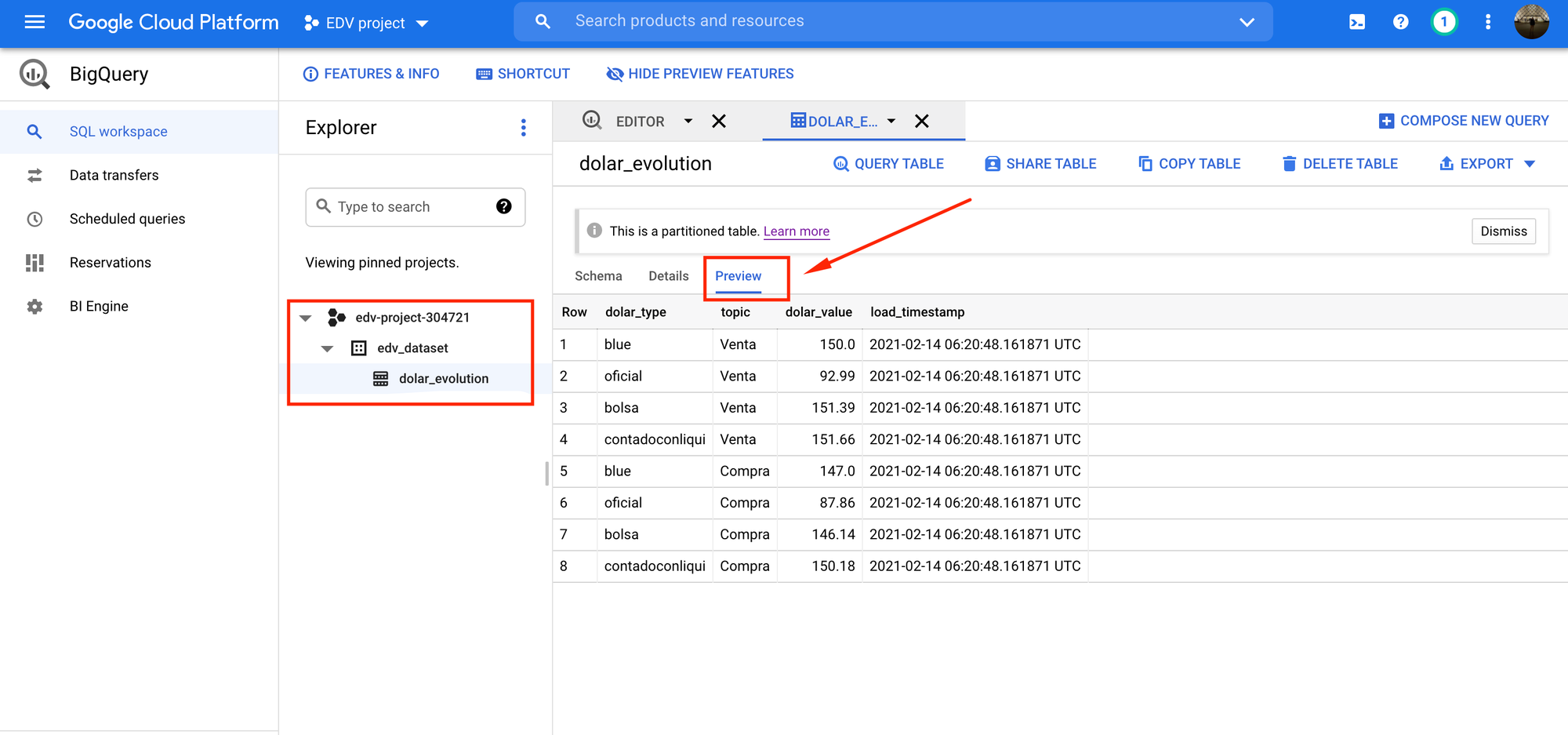
Podemos ver que la tabla se creo correctamente!! 🎊🎉🎊
Si ejecutamos de nuevo el trigger de la cloud function , los nuevos datos se 'appendearan' al final de la tabla (hacer un refresh en la pagina de BigQuery para ver los nuevos datos):
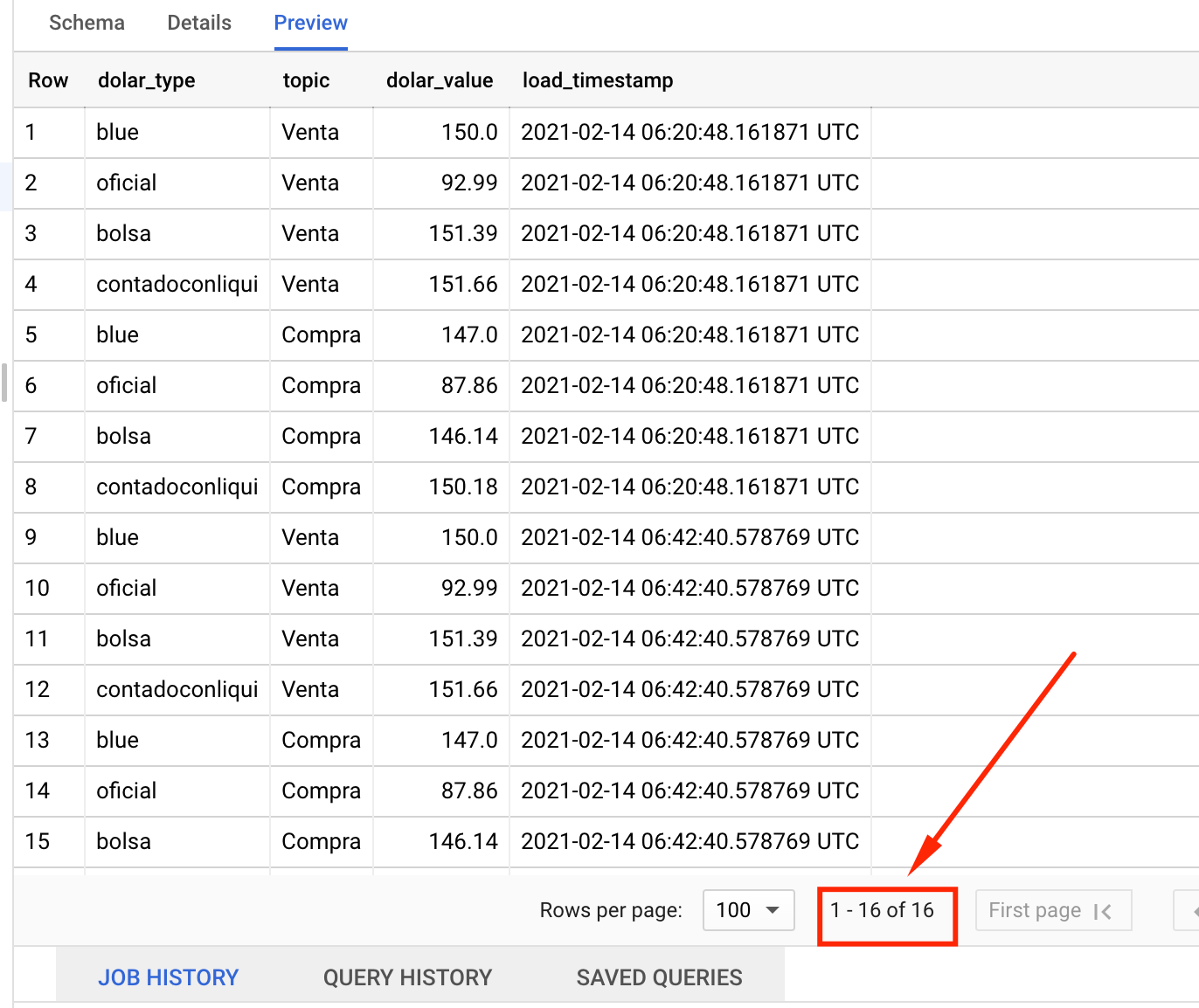
Felicidades! quedo construida tu primer cloud function.
Ahora Es momento de agregar un scheduler para que se ejecute automaticamente cada un cierto intervalo de tiempo.
Tambien es posible generar reportes y Dashboards interactivos conectando Google Data Studio al dataset creado en BigQuery.
Configurando Cloud Scheduler
Cloud Scheduler es un servicio de GCP que permite programar la ejecucion de tareas, abriendo la posibilidad de automatizar practicamente todo.
Para activar este servicio, buscamos cloud scheduler con el buscador de GCP y seleccionamos el primer resultado:

Nos redirigiremos a esta pantalla, donde debemos hacer click en create job:
En la pantalla siguiente nos pedirá que especifiquemos la región, solo ponemos next. Finalmente llegaremos a esta pantalla:
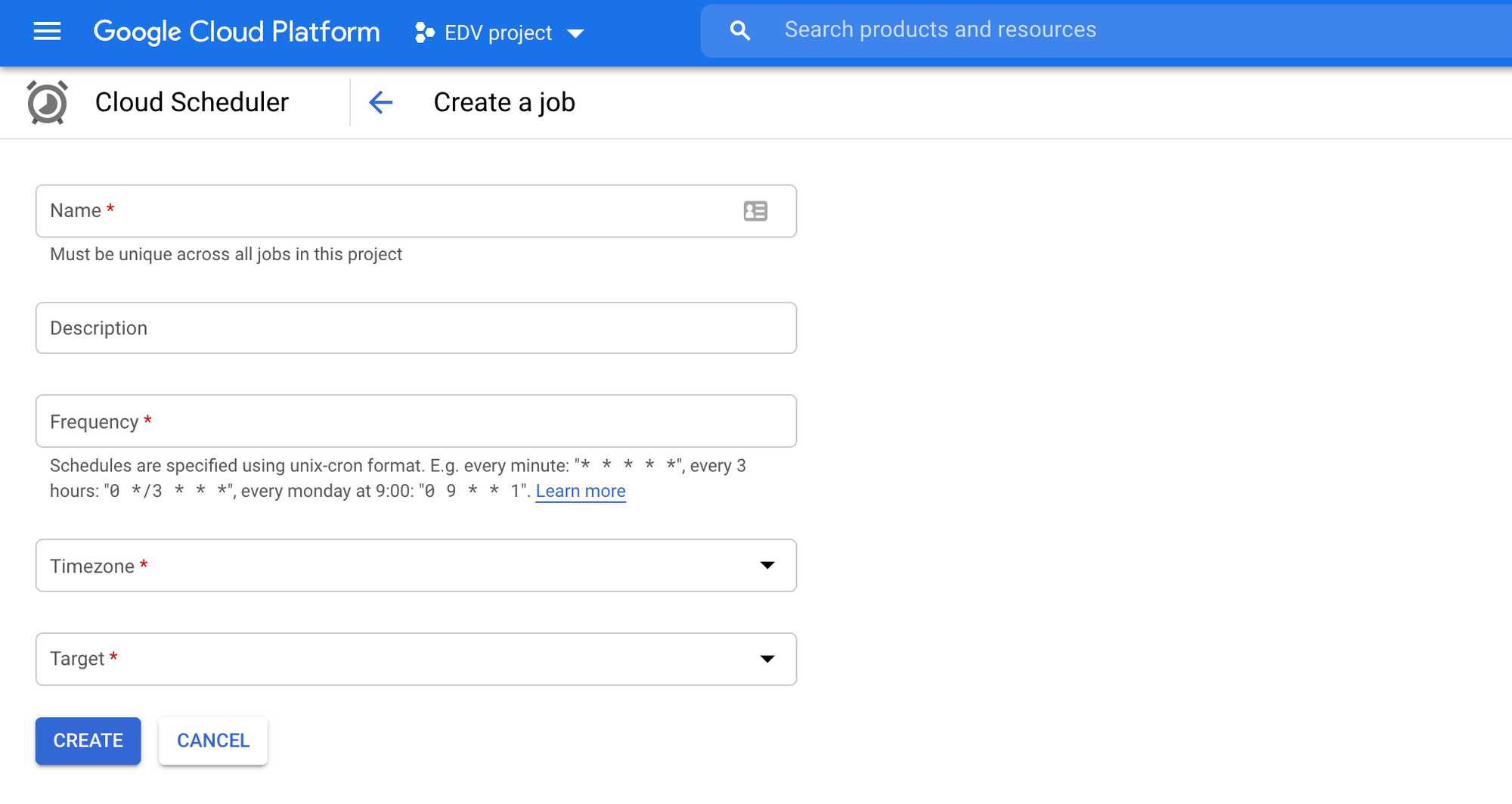
Primero se debe poner un nombre cualquiera al scheduler, en este caso pondremos:
edv_scheduler
Luego debemos definir la frecuencia con la que trabajara el scheduler.
El valor por default es * * * * *, esto indica que el scheduler realizara una tarea cada 1 minuto. Cada asterisco representa un campo distinto:
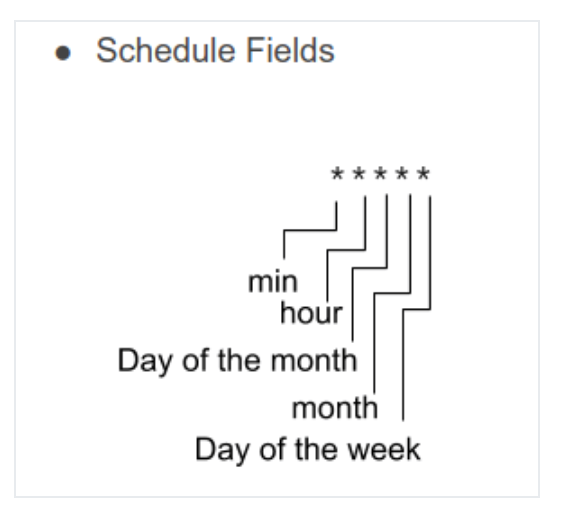
Los posibles valores de cada campo son:
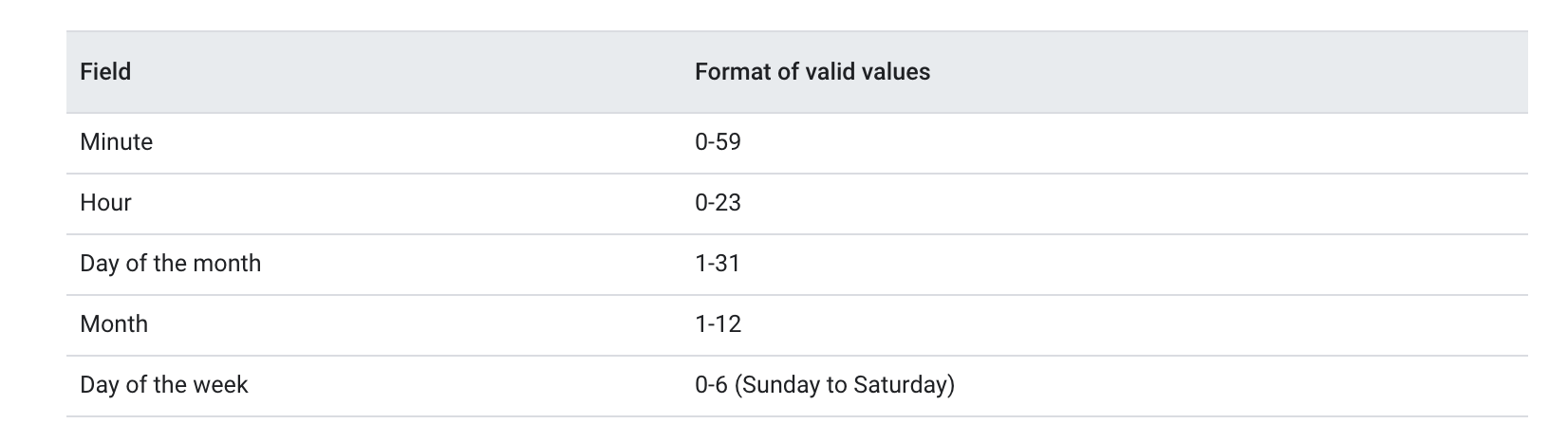
Segun los datos anteriores, algunos ejemplos serian:
cada 1 minuto: * * * * *
cada sabado a las 23:45hs: 45 23 * * 6
cada lunes a las 9:00: 0 9 * * 1
Si tenemos dudas de como armar la frecuencia de trabajo, existe una herramienta muy util llamada cron tab guru, la cual permite elegir la frecuencia del scheduler de una forma muy interactiva.
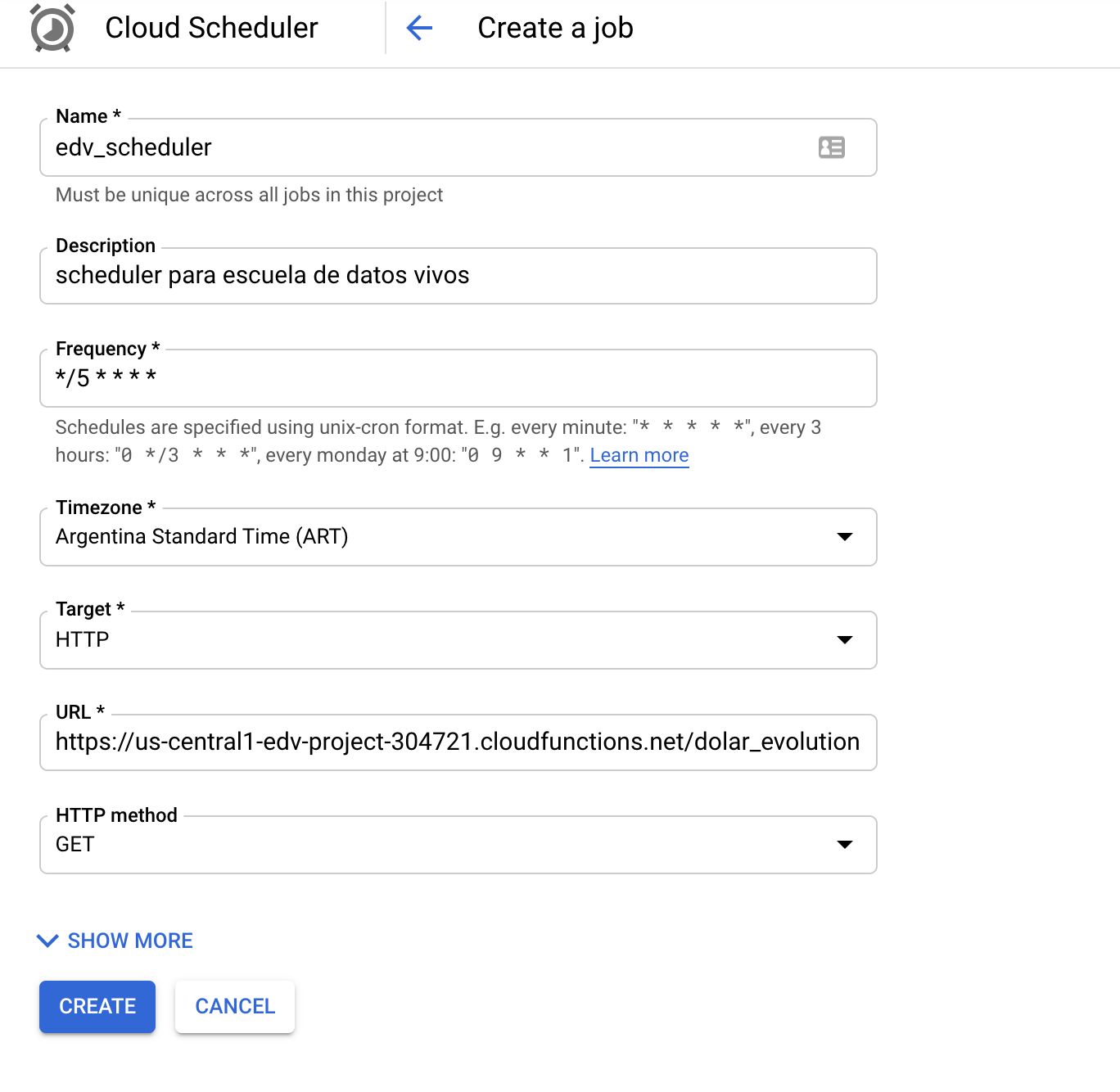
Supongamos que el scheduler debe ejecutar nuestra cloud Function cada 5 minutos (00:00, 00:05, 00:10... 23:55), entonces la frecuencia deberia tomar el siguiente valor:
*/5 * * * * (la barra inclinada indica un step)
Luego de elegir la frecuencia, se debe continuar con la configuracion restante:
En el campo timezone elegimos UTC-3 Buenos Aires.
En el campo target elegimos HTTP.
En el campo URL se debe poner la url del trigger de nuestra Cloud Function (mirar la seccion anterior para recordar como se obtenia el trigger).
En el campo HTTP Method debemos elegir GET.
La configuracion final quedaria asi:
Hacemos click en create y la pagina nos redirige hacia esta vista:

Aqui vemos que el campo last run esta vacio porque todavia no se ejecuto el scheduler. Si esperamos 5 minutos y refrescamos la pagina, notaremos que el campo last run se lleno con la fecha y hora de la ultima ejecucion:

Si vamos a BigQuery, deberiamos poder constatar que la tabla se actualizó con nuevos datos.
Conclusiones
A lo largo de este articulo se trataron muchos temas:
- Request HTTP
- Manejo de depencias
- Google Cloud Platform
- Google Clouds APIs
- Cloud Functions
- Google BigQuery
- Cloud SDK
- Cloud Scheduler
Pero aun así, solo vimos una parte muy minúscula de todo lo que nos ofrece Google Cloud Platform.
La idea principal que debemos llevarnos de todo esto es que, independientemente de nuestro perfil técnico, hay que tener en mente que el Cloud Computing nos otorga muchisimas alternativas para poder llevar nuestros proyectos al siguiente nivel, y es de suma importancia tener un conocimiento mínimo de las herramientas que nos ofrece el mercado.
Por Lain Taljuk.
Publicado originalmente es https://escueladedatosvivos.ai
¿Te interesa seguir aprendiendo?