
Si solo podemos optar por una única alternativa, ¿cómo podemos saber si hemos tomado la decisión correcta? Parece más una pregunta filosófica, pero en realidad son muchas las situaciones cotidianas de una empresa en las que se presentan este tipo de interrogantes. Hoy les quiero contar sobre un caso real sobre cómo la ciencia de datos nos ayudó a entender si habíamos tomado una buena decisión.
Contexto de negocio
Wildlife Studios es la primera empresa de videojuegos en la que trabajo. Suena tan divertido y desafiante como lo es, y no solo por la magia de los juegos sino también por la magia de la publicidad. Quizá alguna vez pensaste en las cosas que pasan detrás del video con publicidad que te aparece al entrar en un juego mobile. Pasan muchas cosas, y son todas apasionantes.
¿Qué es un SDK?
Por lo general en la industria mobile, los encargados de que la publicidad efectivamente llegue a los usuarios son los desarrolladores de una SDK (por sus siglas en inglés, Software Development Kit) específica, que es la que se encarga de conectar la app (juego) con el mercado publicitario. Las SDK son unos paquetes de código que sirven para cumplir partes específicas de la funcionalidad de una app. Una parte de la acción, y de mi trabajo, se da cuando estos softwares necesitan ser mejorados.
Para eso, se crea una nueva versión, se la prueba y finalmente se la lleva a producción. Pero aun después de haberla testeado muchas veces, puede que todavía nos preguntemos si la nueva versión es efectivamente mejor que la anterior. Y si creemos que es mejor, muchas veces queremos saber cuánto mejor es.
A/B Testing y SDKs
Usualmente cuando surgen preguntas de este tipo, en ciencia de datos las respondemos mediante la experimentación. Por ejemplo, diseñando un A/B test. En este caso, podríamos lanzar la nueva SDK para algunos usuarios elegidos aleatoriamente (grupo de tratamiento) y mantener al resto con la versión antigua (grupo de control). Luego compararíamos cómo nos fue en el grupo de la SDK nueva y el de la SDK anterior.

Pero cuando se trata de apps, la versión que importa es la que está disponible en el App Store. Y ahí es cuando nos enfrentamos a la difícil tarea de responder cómo nos ha ido sin poder tener un grupo de control elegido aleatoriamente.
Es cierto que, y dependiendo de la política de actualización de la app, pueden convivir varias versiones al mismo tiempo. Pero sería un error simplemente comparar al grupo de usuarios que tienen la versión nueva con los que tienen versiones anteriores. Dado que los factores que llevan a un usuario a tener la última versión no están distribuidos aleatoriamente entre ambos grupos, y si están asociados a lo que nos interesa medir como métrica de desempeño, una comparación como esa nos llevaría a inflar o subestimar los efectos del cambio de versión.
Por ejemplo, fácilmente podemos imaginar que un usuario que dispone de memoria en su dispositivo puede ser un gran candidato a tener la última versión, mientras que en el caso inverso, no. Pero un usuario de este tipo puede ser también un jugador novato, y por lo tanto comportarse de una manera muy distinta a la de jugadores más experimentados (y con menos memoria en su dispositivo). Esto nos lleva a la próxima sección...
¿Cómo hacemos para saber cuál fue el impacto de cambiar nuestra versión de SDK?
Básicamente, la idea es intentar conocer qué hubiera pasado si ese cambio de versión no hubiera sucedido. Claramente, no hay forma de respondernos esa pregunta sin plantear una situación contrafáctica. Es decir, una situación que podría haber sucedido pero que realmente no sucedió.
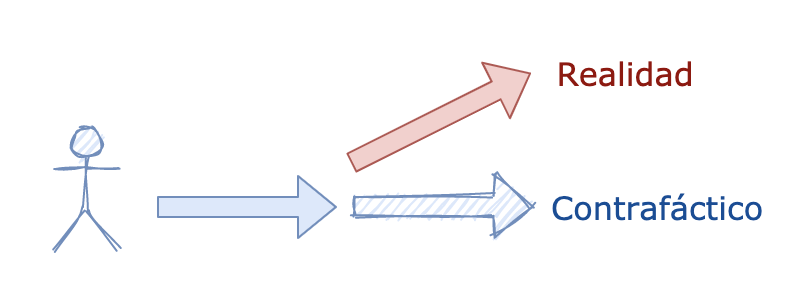
De esta forma, lo que ha sucedido en realidad hará las veces de nuestro grupo de tratamiento, y por su lado, la situación contrafáctica será representada por nuestro grupo de control. Luego podremos comparar ambas situaciones y sacar conclusiones sobre el efecto del cambio de versión.
Un poco de negocio antes
Antes de meternos de lleno con cómo planteamos la situación contrafáctica, me gustaría contarles un poco acerca de la métrica de desempeño que nos interesa analizar. Una de las métricas más precisas para medir el desempeño de distintas estrategias en publicidad mobile es el ARPDAU (por sus siglas en inglés, Average Revenue Per Daily Active Users), que en castellano sería algo así como el ingreso monetario promedio por usuario activo en un día. Esta métrica nos ayuda a abstraernos de los números totales que dependen de otros factores, como cantidad de descargas o cambios en la retención de usuarios. Entonces, monitoreando el ARPDAU podremos saber si estamos logrando o no generar más ingresos con los usuarios que entran a un juego.
Un enfoque más técnico
Volviendo al tema de cómo generar una situación contrafáctica: un razonamiento simple pero potente es suponer que si no hubiéramos cambiado nada entonces nada hubiese cambiado. Imaginemos que nos encontramos en una situación donde nuestra métrica de interés (ARPDAU) se mantiene siempre aproximadamente dentro de los mismos valores. Como podemos observar en el siguiente esquema, sería razonable pensar que en ausencia de cambios, la métrica hubiera mantenido su valor.
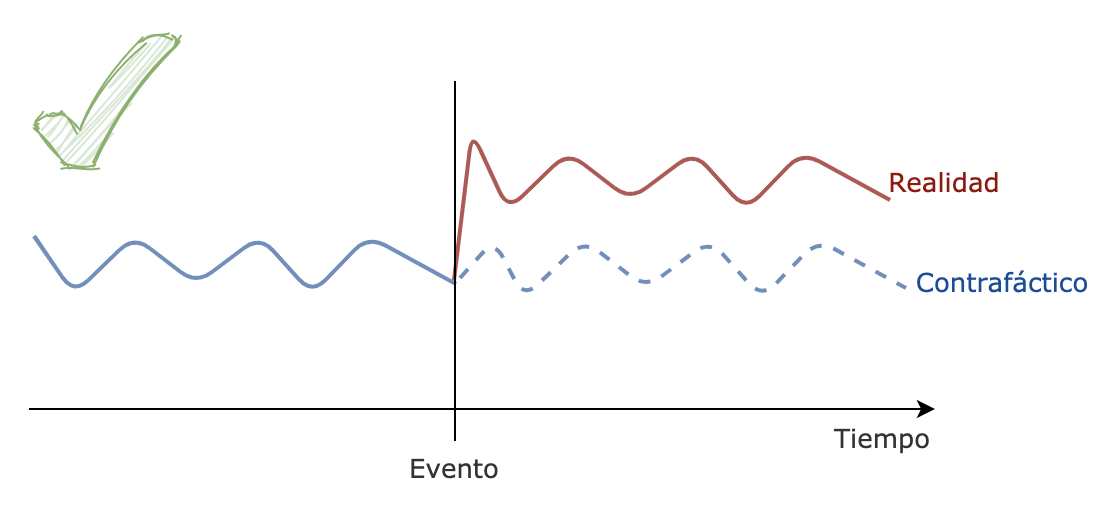
Pero ahora imaginemos que la métrica tuviera una tendencia positiva a lo largo del tiempo, plantear un contrafactual que simplemente replique lo que sucedió en el periodo anterior al evento de cambio de versión sería un error. Como podemos ver en la representación siguiente, en este ejemplo la comparación con tal situación contrafáctica sobrevaloraría el impacto de nuestra nueva versión.
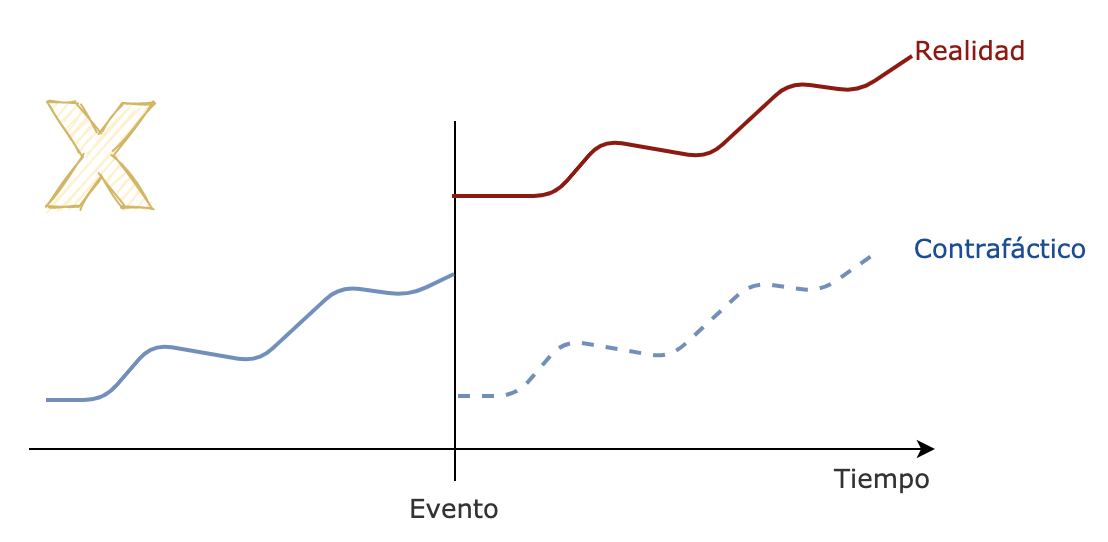
Entonces para mejorar nuestra estimación de la situación contrafáctica, podríamos plantearnos que lo que se hubiera mantenido en ausencia de la introducción de la nueva versión son aquellos elementos preexistentes que de alguna manera gobernaban la evolución de ARPDAU. Estos serían, principalmente, la tendencia, los ciclos y la estacionalidad de esta serie. Un contrafactual que incluya esos elementos nos daría una muy buena base para medir el impacto de nuestra intervención.
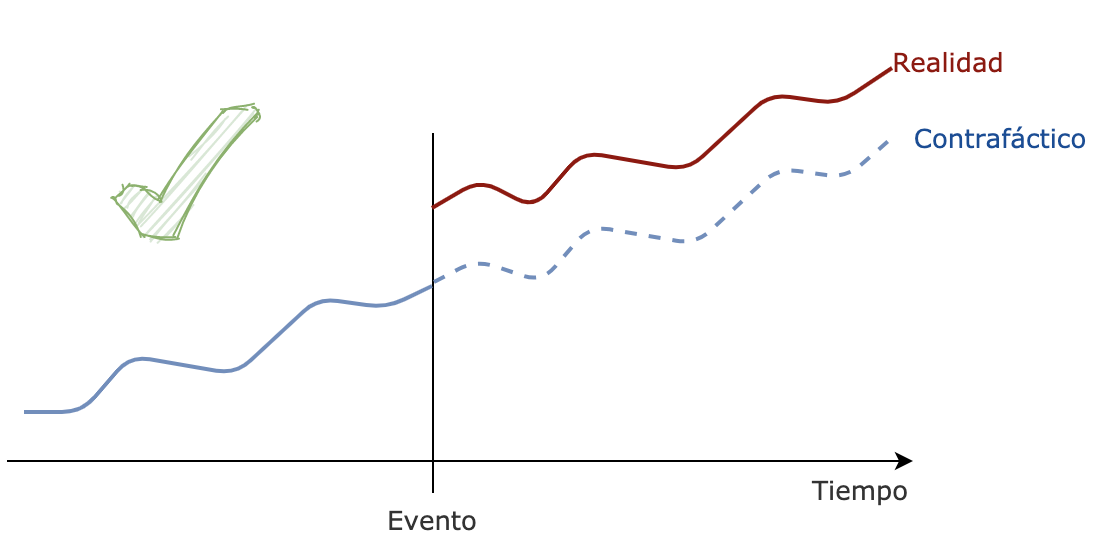
Pero no es tan sencillo, porque si bien ahora nos encontramos en una situación muchísimo más comparable, pueden existir factores inesperados que afecten nuestra inferencia. Por ejemplo, dentro del mundo de la publicidad online, pueden darse caídas abruptas aunque quizá temporales de algunos de los grandes compradores, conocidos como adnets.
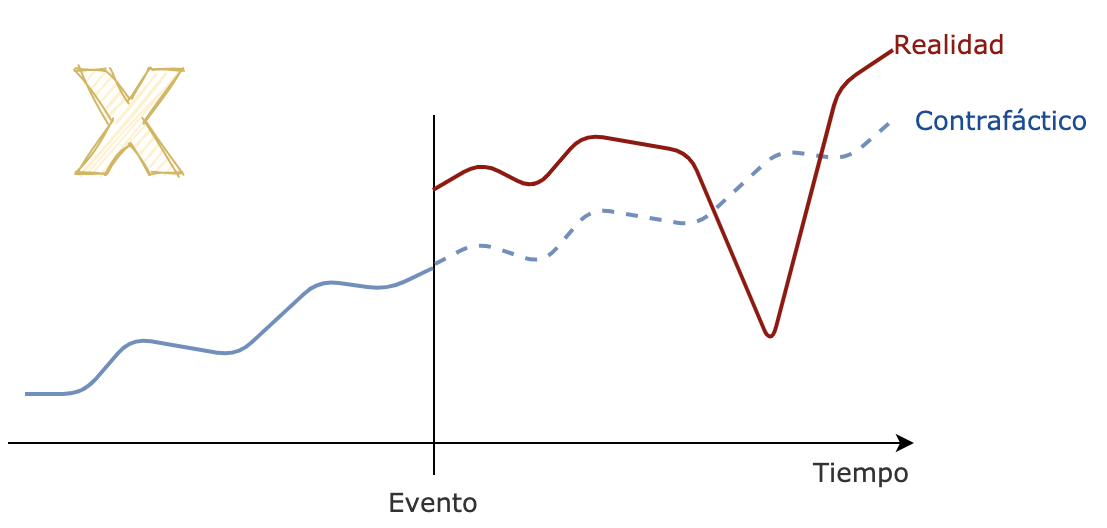
En dicho caso, algo que nos puede ayudar es analizar qué pasa con las métricas de interés en otros juegos que no usan nuestra nueva versión, para intentar con ellos construir un contrafáctico más robusto ante esos eventos inesperados.
R, Impacto causal y el equipo de Google
Ahora necesitamos un método que sea capaz de incorporar todos estos elementos necesarios para armar un buen contrafáctico. Una parte importante de la tarea es aprender a predecir la serie temporal. Para eso debemos capturar características como tendencia, estacionalidad y los ciclos. Pero también, tenemos que emprender la difícil tarea de elegir cuál de todos los otros juegos (Wildlife Studios tiene muchos) usaremos para completar nuestro escenario contrafáctico, es decir, nuestro grupo de control. Una manera muy elegante de solucionar todos estos desafíos a la vez fue planteada por el equipo de Google. Gracias a ese trabajo, tenemos a disposición tanto un artículo con la explicación académica, como un paquete de R llamado CausalImpact.
Solución propuesta: el enfoque bayesiano
La solución plantea hacer uso de un modelo estructural de series de tiempo, dentro de un enfoque bayesiano. A no asustarse, lo importante es que este tipo de modelo nos permitirá explicitar cada uno de los componentes del tan ansiado contrafáctico.
Omitiré contarles cómo se obtienen la tendencia y la estacionalidad, que seguramente en cualquier curso de análisis de series temporales pueden aprender. Voy a saltar directamente a la parte más interesante de la estimación, que es cómo haremos uso de la información que viene de los otros juegos.
El mejor escenario que nos podríamos encontrar es un juego o un grupo de juegos que se comporten de manera muy similar al juego que estamos intentando analizar. Pero en realidad, nos encontramos con muchos juegos que pueden tener una correlación más o menos fuerte con la serie temporal que nos interesa modelar. ¿Cómo soluciona el paquete esta dificultad? Mediante el uso de una técnica bayesiana de selección de variables, que en inglés se llama "spike-and-slab", vamos a poder determinar en qué grado incluir una determinada covariable contemporánea (un juego) como predictora de la serie temporal. Lo que nos permite saber qué juegos usar y qué peso darles. Y lo mejor de todo, como es útil para seleccionar variables en escenarios donde el número de predictores supera el número de observaciones, ¡podemos poner a prueba cuantos juegos queramos!
Los resultados!
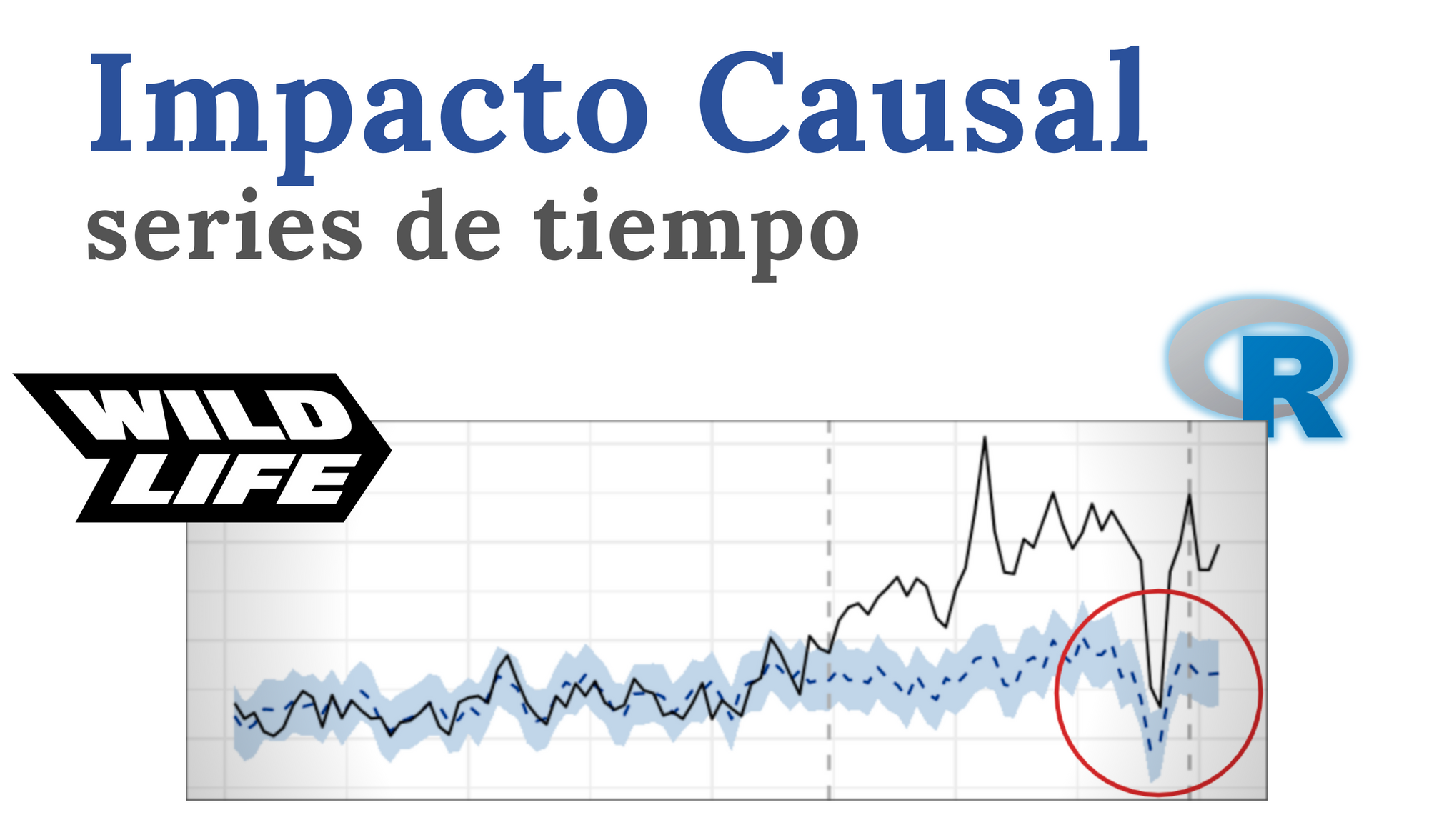
Finalmente, ¿cómo han sido los resultados? Robustos en la mayoría de los casos. En el siguiente gráfico podemos ver cómo para algunos juegos el lanzamiento de la nueva SDK tuvo un impacto neutro en la métrica. Esto se puede ver comparando la métrica real (línea negra continua) con la situación contrafáctica (línea azul punteada), después del lanzamiento de la SDK (primera línea gris punteada vertical). Por temas de privacidad, se eliminan los valores absolutos, pero se puede apreciar que el margen de error es relativamente bajo.
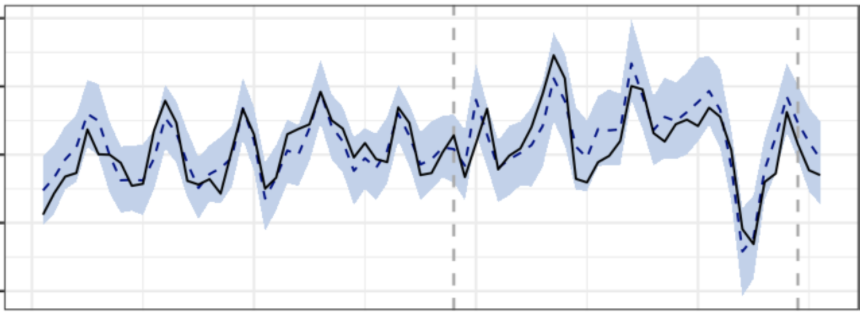
También en otros juegos tuvimos una buena experiencia, en varios sentidos. No solo mostrando el impacto positivo del lanzamiento de la SDK, sino también prediciendo situaciones atípicas como la que marca el círculo rojo. Particularmente, esta caída estuvo relacionada a una situación generalizada posterior a las elecciones presidenciales en Estados Unidos. ¡Punto para haber usado esta técnica que incluye otros juegos como predictores!
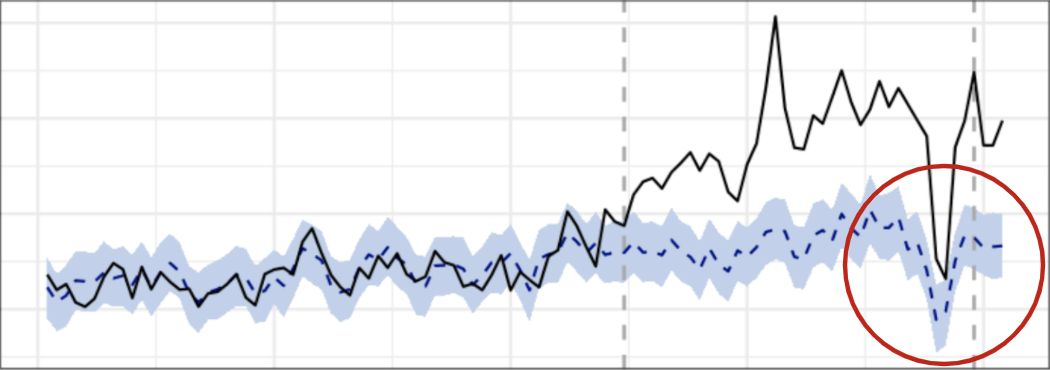
Otras situaciones no fueron tan felices
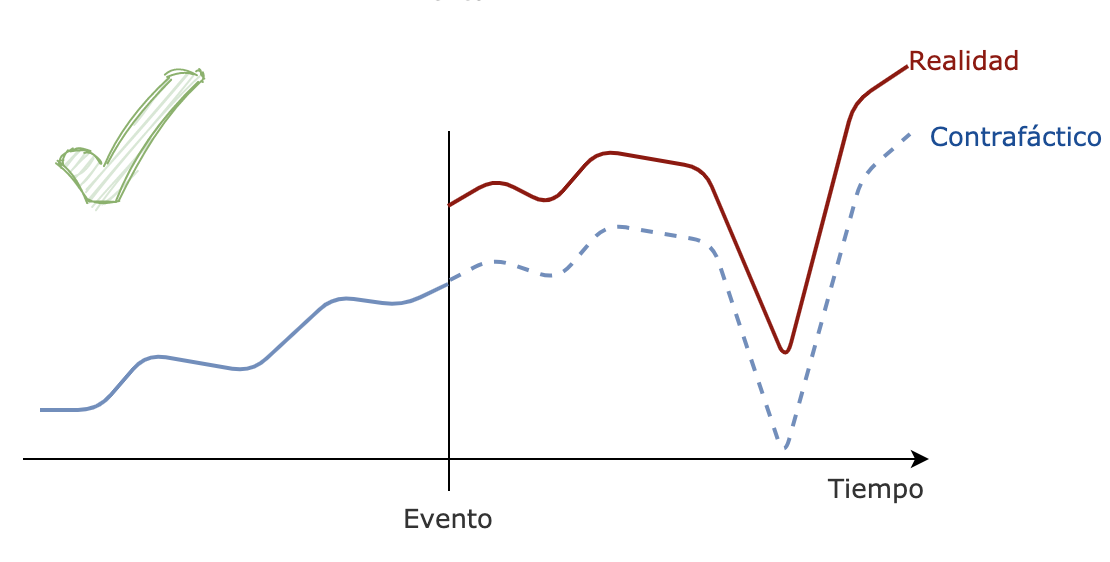
Por ejemplo, en el siguiente gráfico se ve una situación inesperada que solo ocurrió en el juego en cuestión y la inferencia con la situación contrafactual sobreestimó ampliamente el impacto del evento. Aislar este efecto implicó excluir parte de los ingresos que generaron este salto extra.
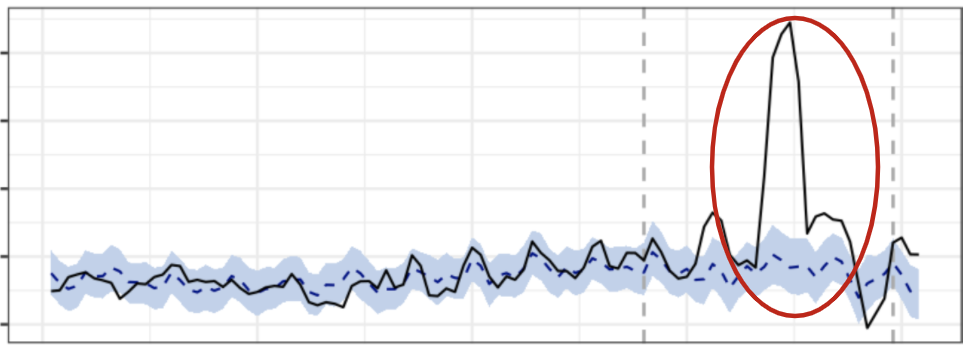
Implementación en R
Lo mejor de todo es que a nivel implementación no requiere grandes esfuerzos. Una demostración sencilla es que no se necesita más de 10 líneas de código, como se muestra a continuación.
# Importar la librería
library(CausalImpact)
# Levantar el data frame. Cada columna representa la serie
# temporal de cada uno de los juegos, ordenada ascendentemente
# por periodo temporal. Es importante mencionar que la primera
# columna es el juego a evaluar y el resto de las columnas son
# los otros juegos que se usarán como covariables.
df <- SparkR::sql(“SELECT * FROM temp_df”) %>% SparkR::collect() %>% as_tibble
# Delimitar el período de entrenamiento del modelo (pre.period)
# y el período contrafactual (post.period)
pre.period <- c(1, 60) # Se toma los primeros 60 días para el entrenamiento
post.period <- c(61, 75) # Se evalúa el impacto con los 25 días posteriores
# Ajustar el modelo (la parametrización es opcional)
impact <- CausalImpact(df, pre.period, post.period, model.args = list(nseasons = 7))
# Evaluar del modelo
plot(impact) # Inspección visual del ajuste
summary(impact) # Resumen numérico de las estadísticas principales y del ajuste del modelo
summary(impact, "report") # Resumen redactado de las estadísticas principales y del ajuste del modelo
Conclusiones
Los resultados fueron muy robustos y permitieron poner un número al esfuerzo de generar una versión completamente renovada de la SDK. La posibilidad de hacer uso de otros juegos como predictores fue clave. Y finalmente, haberlo aplicado rápidamente fue una ventaja, dado que el paquete de CausalImpact es bastante intuitivo y requiere poco esfuerzo para su implementación.
Espero que hayan disfrutado la lectura tanto como yo haber escrito este blogspot. ¡Y a seguir disfrutando de la ciencia de datos, y de los juegos!
Escrito por Micaela Morales de Wildlife Studios.
Edición por Escuela de Datos Vivos.
Bibliografía