
Resumen: El análisis exploratorio de datos (AED) es el primer paso en un proyecto de datos. Crearemos un template de código para hacerlo con solo una función.
Introducción
El AED consiste en un análisis univariado (1-variable) y bivariado (2-variables).
En este artículo revisaremos algunas funciones que nos llevan al análisis del primer caso.
- Paso 1 - Primer acercamiento a los datos
- Paso 2 - Analizar las variables categóricas
- Paso 3 - Analizar las variables numéricas
- Paso 4 - Analizar numérico y categórico al mismo tiempo
Abarcando algunos puntos clave en un AED básico:
- Tipos de datos
- Los valores atípicos (outliers)
- Los valores faltantes (nulos)
- Análisis de distribuciones (numéricas y gráficas) para ambos tipos.
💻 Este post está estrechamente relacionado con el curso Desembarcando en R > 2da Edición, pueden anotarse gratis acá, o ir a la versión paga con soporte y certificado, aquí!
Fin de pauta publicitaria, sigamos con el post!
Tipo de resultados de los análisis
Pueden ser dos: informativos u operativos.
Informativas - Por ejemplo, gráficos, o cualquier resumen largo de variables. No podemos filtrar los datos de él, pero nos da mucha información a la vez. La más utilizada en la etapa AED.
Operativo - Los resultados pueden ser usados para tomar una acción directamente en el flujo de trabajo de los datos (por ejemplo, seleccionando cualquier variable cuyo porcentaje de valores faltantes esté por debajo del 20%). Más utilizado en la etapa Preparación de datos.
Preparación
Descomentar en caso de que no tengas ninguna de estas librerías:
# install.packages("tidyverse")
# install.packages("funModeling")
# install.packages("Hmisc")
library(funModeling)
library(tidyverse)
library(Hmisc)Si ya tienen funModeling, recuerden volver a instalarla para disponer de las últimas funciones y fixes.
Resumen de código
Ejecutar todas las funciones de este post de una sola vez con la siguiente función:
basic_eda <- function(data)
{
glimpse(data)
print(status(data))
freq(data)
print(profiling_num(data))
plot_num(data)
describe(data)
}Remplacen data con sus datos, y eso es todo! 🎉
aed_basico(mis_super_datos)
<br>
Creando los datos para este ejemplo
Usando los datos de heart_disease (del paquete funModeling). Tomaremos sólo 4 variables para su legibilidad.
data=heart_disease %>% select(age, max_heart_rate, thal, has_heart_disease)Paso 1 - Primer acercamiento a los datos
Número de observaciones (filas) y variables, y una muestra de los primeros casos.
glimpse(data)
## Observations: 303
## Variables: 4
## $ age <int> 63, 67, 67, 37, 41, 56, 62, 57, 63, 53, 57, ...
## $ max_heart_rate <int> 150, 108, 129, 187, 172, 178, 160, 163, 147,...
## $ thal <fct> 6, 3, 7, 3, 3, 3, 3, 3, 7, 7, 6, 3, 6, 7, 7,...
## $ has_heart_disease <fct> no, yes, yes, no, no, no, yes, no, yes, yes,...
Obteniendo las métricas sobre tipos de datos, ceros, números infinitos y valores perdidos:
status(data)
## variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
## 1 age 0 0 0 0.0000 0 0 integer 41
## 2 max_heart_rate 0 0 0 0.0000 0 0 integer 91
## 3 thal 0 0 2 0.0066 0 0 factor 3
## 4 has_heart_disease 0 0 0 0.0000 0 status devuelve una tabla, así que es fácil tener las variables que coincidan con ciertas condiciones como:
+ Tener al menos el 80% de los valores no-NA (p_na < 0.2)
+ Tener menos de 50 valores únicos (unique <= 50)
💡 TIPS:
- ¿Todas las variables están en el tipo de datos correcto?
- ¿Variables con muchos ceros o
NAs? - ¿Alguna variable de alta cardinalidad?
[🔎 Leer más aquí]
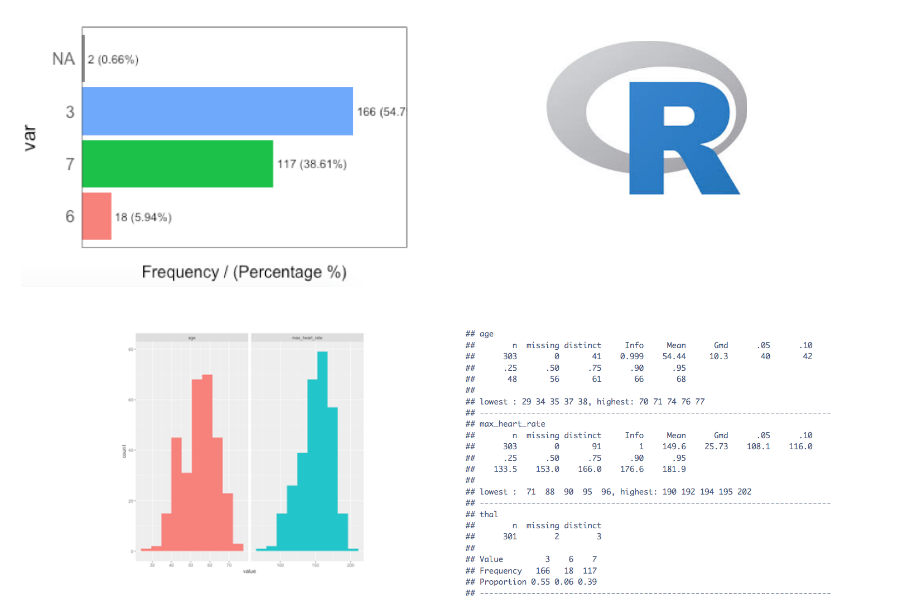
Paso 2: Analizar las variables categóricas
La función freq se ejecuta automáticamente para todas las variables factor o character.
freq(data)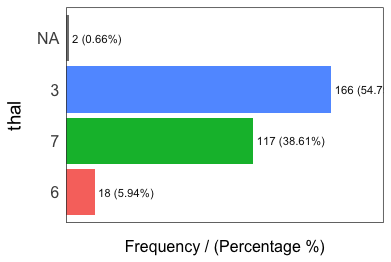
## thal frequency percentage cumulative_perc
## 1 3 166 54.79 55
## 2 7 117 38.61 93
## 3 6 18 5.94 99
## 4 <NA> 2 0.66 100
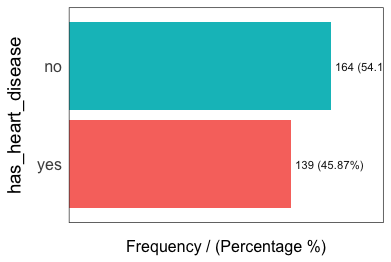
## has_heart_disease frequency percentage cumulative_perc
## 1 no 164 54 54
## 2 yes 139 46 100
## [1] "Variables processed: thal, has_heart_disease"
💡 TIPS:
- Si
freqrecibe una variable -freq(data$variable)-, se devuelve una tabla. Esto es útil para tratar variables de alta cardinalidad (como el código postal). - Exportar las gráficas a jpeg en el directorio actual:
freq(data, path_out = ".") - ¿Todas las categorías tienen sentido?
- ¿Muchos valores perdidos (
NA)? - Siempre comprobar los valores absolutos y relativos
[🔎 Leer mas aquí]
Paso 3 - Analizar las variables numéricas
Ya veremos: plot_num y profiling_num. Ambos se ejecutan automáticamente para todas las variables numéricas y enteras:
Visualmente
plot_num(data)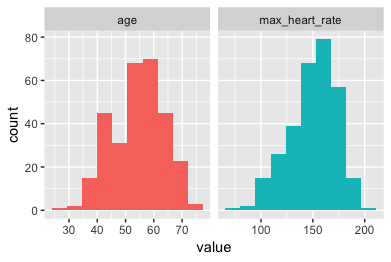
Exportar el gráfico a jpeg: plot_num(data, path_out = ".")
💡 TIPS:
- Identificar las variables desbalanceadas
- Comprobar visualmente cualquier variable con valores atípicos (outliers)
[🔎 Leer más aquí]
Cuantitativamente
La función profiling_num se ejecutará para todas las variables numericas/integer automáticamente:
data_prof=profiling_num(data)
## variable mean std_dev variation_coef p_01 p_05 p_25 p_50 p_75 p_95
## 1 age 54 9 0.17 35 40 48 56 61 68
## 2 max_heart_rate 150 23 0.15 95 108 134 153 166 182
## p_99 skewness kurtosis iqr range_98 range_80
## 1 71 -0.21 2.5 13 [35, 71] [42, 66]
## 2 192 -0.53 2.9 32 [95.02, 191.96] [116, 176.6]
💡 TIPS:
- Describir cada variable en función de su distribución (también útil para la presentación de informes)
- Prestar atención a las variables con altp desvio estándar.
- Seleccionar las métricas con las que esté más familiarizado:
data_prof %>% select(variable, variation_coef, rango_98): Un valor alto envariation_coefpuede indicar valores atípicos.rango_98indica dónde están la mayoría de los valores.
[🔎 Leer más aquí]
Paso 4 - Análisis de variables numéricas y categóricas al mismo tiempo
Usaremos la función describe del paquete Hmisc.
library(Hmisc)
describe(data)
## data
##
## 4 Variables 303 Observations
## ---------------------------------------------------------------------------
## age
## n missing distinct Info Mean Gmd .05 .10
## 303 0 41 0.999 54.44 10.3 40 42
## .25 .50 .75 .90 .95
## 48 56 61 66 68
##
## lowest : 29 34 35 37 38, highest: 70 71 74 76 77
## ---------------------------------------------------------------------------
## max_heart_rate
## n missing distinct Info Mean Gmd .05 .10
## 303 0 91 1 149.6 25.73 108.1 116.0
## .25 .50 .75 .90 .95
## 133.5 153.0 166.0 176.6 181.9
##
## lowest : 71 88 90 95 96, highest: 190 192 194 195 202
## ---------------------------------------------------------------------------
## thal
## n missing distinct
## 301 2 3
##
## Value 3 6 7
## Frequency 166 18 117
## Proportion 0.55 0.06 0.39
## ---------------------------------------------------------------------------
## has_heart_disease
## n missing distinct
## 303 0 2
##
## Value no yes
## Frequency 164 139
## Proportion 0.54 0.46
## ---------------------------------------------------------------------------
Es muy útil para tener una imagen rápida de todas las variables. Pero no es tan operativo como freq y profiling_num cuando queremos usar sus resultados para cambiar nuestro flujo de datos.
💡 TIPS:
- Comprobar los valores mínimos y máximos (valores atípicos)
- Verificar las distribuciones (igual que ántes)
[🔎 Leer más aquí]
En la escuela tenemos un curso super completo llamado Ciencia de Datos 360 con R.🤓 [soporte y certificado]